CUME_DIST is a very nice & helpful analytical function introduced in SQL SERVER 2012. In this article, we will discuss its syntax, purpose, return type, simple examples and real world examples also.
syntax
CUME_DIST( )
OVER ( [ partition_by_clause ] order_by_clause )
purpose
The purpose of this function is to calculate the cumulative distribution of value in a group of values.
Return Type
The return type is float(53) and the values are always between 0 and 1.
Example 1 : Simple CUME_DIST ()
Lets take gold rates as an example to check their cumulative distribution in one week.
Create table [Daily_Gold_Rate]
(
(
[S.No] int,
[Date] datetime,
[Carat] int,
[Gold Rate] numeric(18,2)
)
Insert into [Daily_Gold_Rate] values(1,'2012-12-03',18,155.00)
Insert into [Daily_Gold_Rate] values(4,'2012-12-04',18,153.00)
Insert into [Daily_Gold_Rate] values(7,'2012-12-05',18,152.00)
Insert into [Daily_Gold_Rate] values(10,'2012-12-06',18,154.50)
Insert into [Daily_Gold_Rate] values(13,'2012-12-07',18,154.50)
GO
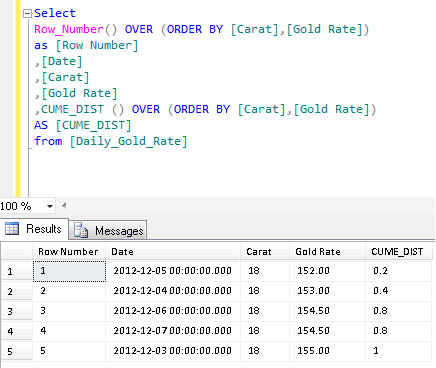
Select
Row_Number() OVER (ORDER BY [Carat],[Gold Rate]) as [Row Number]
,[Date]
,[Carat]
,[Gold Rate]
,CUME_DIST () OVER (ORDER BY [Carat],[Gold Rate]) AS [CUME_DIST]
from [Daily_Gold_Rate]
Explanation :
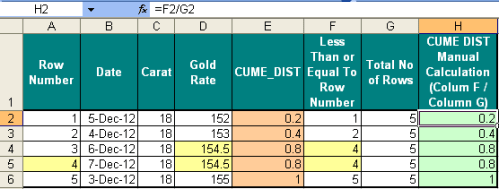
If you look at Column E and Column H, Column E is calculated by SQL Server and Column H is calculated manually to understand how it works. To calculate CUME_DIST manually, you need two values.
1. Row Number based on the values (Meaning less than or equal to value) (Column F)
2. Total Number of Records (Column G)
Column G is simple; you need to calculate the total number of records.
Column F: You simply need to get the row number based on the values. You can observe that it is simple row number till row number 2 but in row number 3 & 4 we found the same Gold rate, so it picked up 4 (due to less than or equal to value criteria) as row number.
Finally, you need to divide Column F by Column G to get the CUME_DIST manually. The same functionality CUME_DIST does automatically in SQL.
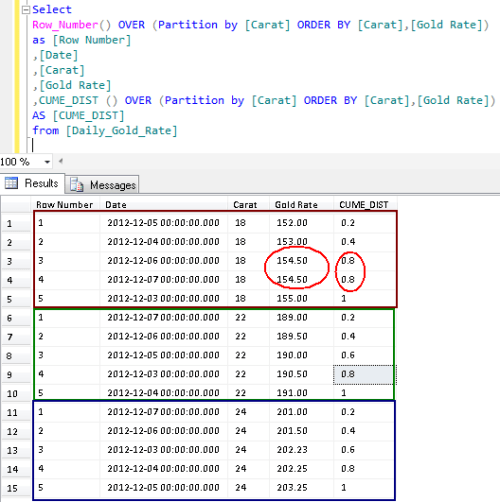
Example 2 : CUME_DIST () with Partition By Clause
Lets insert other Gold rates to proceed with this example.
Insert into [Daily_Gold_Rate] values(2,'2012-12-03',22,190.50)
Insert into [Daily_Gold_Rate] values(3,'2012-12-03',24,202.23)
Insert into [Daily_Gold_Rate] values(5,'2012-12-04',22,191.00)
Insert into [Daily_Gold_Rate] values(6,'2012-12-04',24,202.25)
Insert into [Daily_Gold_Rate] values(8,'2012-12-05',22,190.00)
Insert into [Daily_Gold_Rate] values(9,'2012-12-05',24,203.25)
Insert into [Daily_Gold_Rate] values(11,'2012-12-06',22,189.50)
Insert into [Daily_Gold_Rate] values(12,'2012-12-06',24,201.50)
Insert into [Daily_Gold_Rate] values(14,'2012-12-07',22,189.00)
Insert into [Daily_Gold_Rate] values(15,'2012-12-07',24,201.00)
Select
Row_Number() OVER (Partition by [Carat] ORDER BY [Carat],[Gold Rate])
as [Row Number]
,[Date]
,[Carat]
,[Gold Rate]
,CUME_DIST () OVER (Partition by [Carat] ORDER BY [Carat],[Gold Rate])
AS [CUME_DIST]
from [Daily_Gold_Rate]
Reference :MSDN
Read Full Post »