WeatherAPI provides an API to get Weather condition of any location. In this article, we will use this API in SQL Server in order to get weather conditions of any location.
Let me explain it step by step.
Step 1:
Please Sign Up in WeatherAPI and create an account as shown below.

Step 2:
After Sign Up, login to the account, created in Step 1, it will direct to the screen where you can find your API key as shown below, please make a note of this Key.

Step 3:
You need to run given below script to enable OLE Automation Procedures. This is a prerequisite for next step.
sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_configure 'Ole Automation Procedures', 1; GO RECONFIGURE; GO
Step 4:
Let’s create given below stored procedure which takes location as an input and provides weather condition of that location.
USE tempdb GO CREATE OR ALTER PROCEDURE sp_Weather_Details @Location NVARCHAR(250) AS DECLARE @URL NVARCHAR(250) = 'https://api.weatherapi.com/v1/current.json'; DECLARE @key VARCHAR(250) ='xxxxxxxxxxxxxxxxxxxxxxxxx'; --Enter your own API Key generated in Step 2 DECLARE @ConsolidatedURL NVARCHAR(250) = CONCAT(@URL,'?key=',@Key,'&q=',@location,'&aqi=no'); DECLARE @Object INT; DECLARE @Json TABLE(DATA NVARCHAR(MAX)); DECLARE @ResponseText NVARCHAR(MAX); EXEC sp_OACreate 'MSXML2.XMLHTTP', @Object OUT; EXEC sp_OAMethod @Object, 'OPEN', NULL, 'GET', @ConsolidatedURL, 'FALSE'; EXEC sp_OAMethod @Object, 'SEND'; EXEC sp_OAMethod @Object, 'RESPONSETEXT', @ResponseText OUTPUT , @Json OUTPUT; INSERT INTO @Json exec sp_OAGetProperty @Object, 'RESPONSETEXT'; DECLARE @Data NVARCHAR(MAX) = (SELECT DATA FROM @Json); SELECT * FROM OPENJSON(@Data) WITH ( [Country] NVARCHAR(500) '$.location.country', [Region] NVARCHAR(500) '$.location.region', [City] NVARCHAR(500) '$.location.name', [Current Temprature] NUMERIC(18,1) '$.current.temp_c', [Humidity] NUMERIC(18,1) '$.current.humidity', [Weather Condition] NVARCHAR(500) '$.current.condition.text', [Wind Speed] NUMERIC(18,1) '$.current.wind_kph' ); GO
Let’s run few examples and see the weather conditions.
- Example 1:
Location: Karachi, Pakistan
USE tempdb GO EXEC sp_Weather_Details 'Karachi'; GO

- Example 2:
Location: Dubai, UAE
USE tempdb GO EXEC sp_Weather_Details 'Dubai'; GO

- Example 3:
Location: London, UK
USE tempdb GO EXEC sp_Weather_Details 'London'; GO
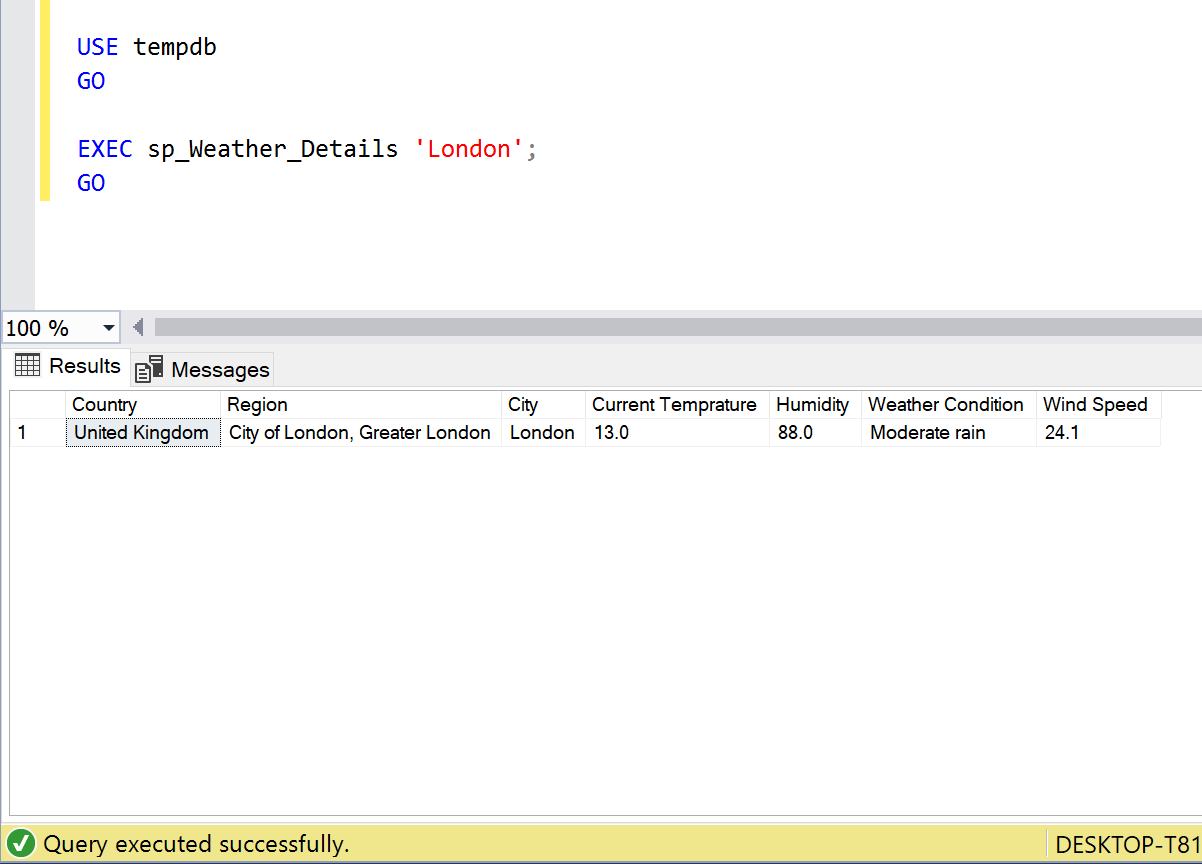
Example 4:
Location: New York, USA
USE tempdb GO EXEC sp_Weather_Details 'New York'; GO

Conclusion:
I found this API very useful whenever I need to find the weather of any location. Do let me know your feedback.