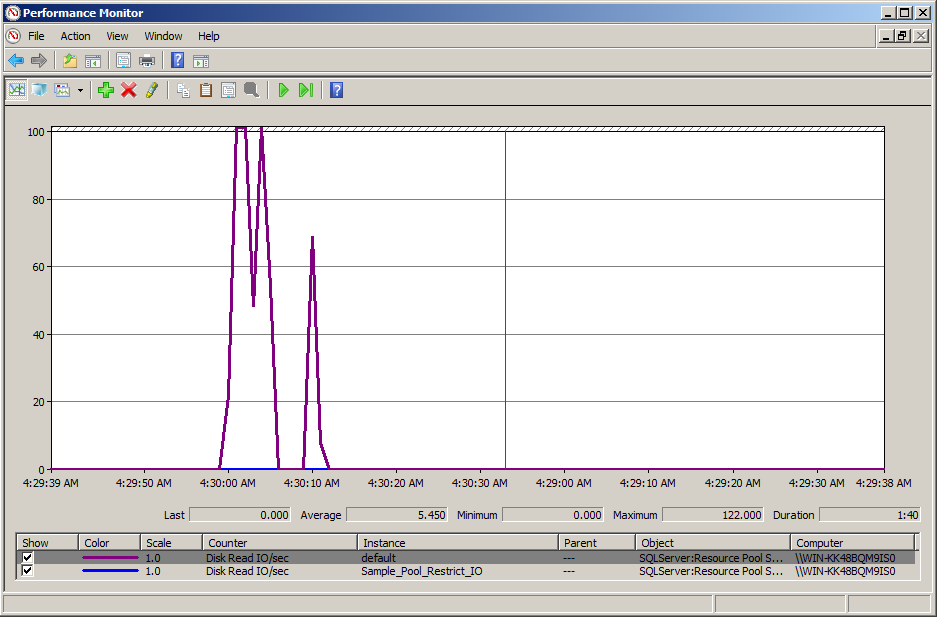
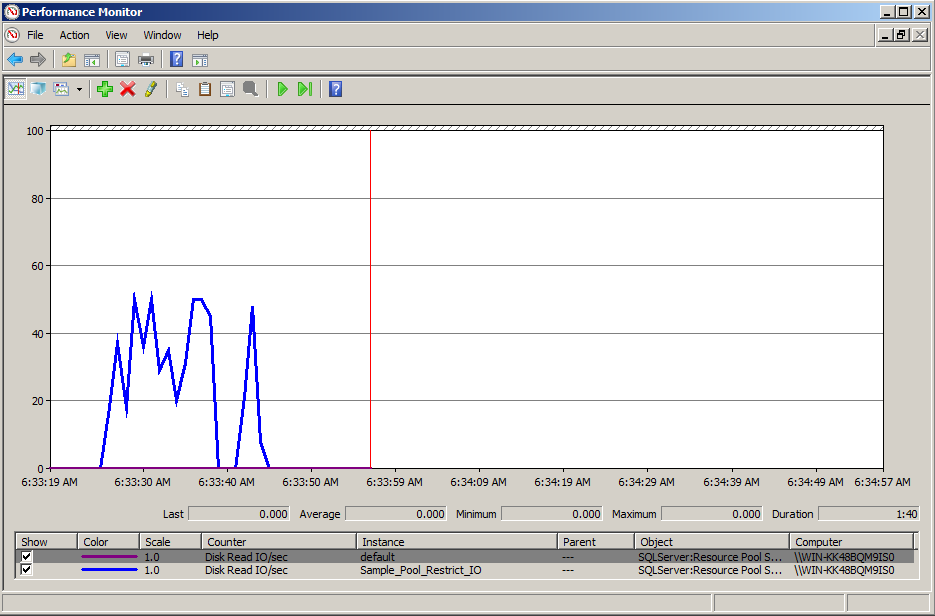
Policy Based Management (PBM) is one of the greatest features shipped with SQL Server 2008. It made DBA’s life easier when it comes to implementation, compliance as well as changing any database/ server properties, especially when you need to implement /check some database / server settings across the databases/ servers. Recently, we have implemented Delayed durability database setting to Forced in one of our clients’ databases using Policy Based Management across the databases. Delayed durability is actually one of the best features shipped with SQL Server 2014. What made it best actually is its handling vs performance. You can just enable with a single statement and you get a huge performance boast.
Note: Delayed durability is disabled by default.
In this article, I will show you step by step, how to implement any database / server settings across the databases / servers using few clicks with the help of Policy Based Management.
Step 1:
Open SQL Server Management Studio (SSMS) and Select Management >>Policy Management >>Conditions and right click on it to Select New Condition… as shown below.

Step 2:
Now, we are in condition building screen, so lets build the 1st condition and that is to check delayed durability in all user databases which is online ONLY. Given below is the configuration. Do not forget to give a proper name to this condition.
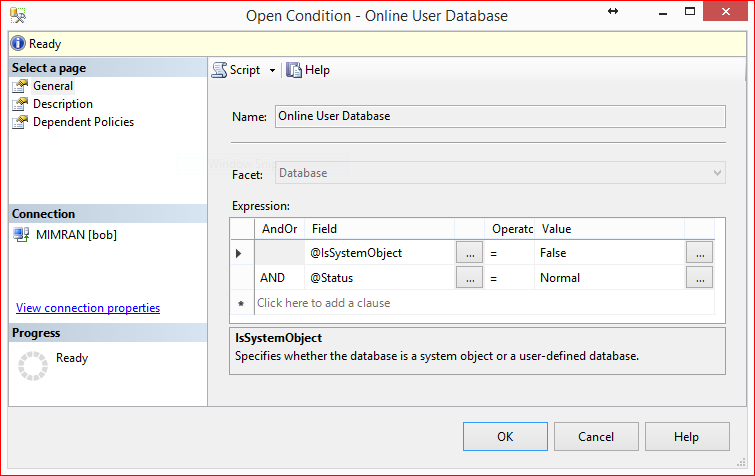
Step 3:
Lets repeat Step 1 and open the condition creation screen. This time we will create the condition to check database setting which is delayed durability=FORCED. Given below is the configuration.

Step 4:
Now we are done with the conditions, so the next step is to build the Policy. In order to build the policy you need to Select Management >>Policy Management >> Policies and right click on it to select New Policy… as shown below.
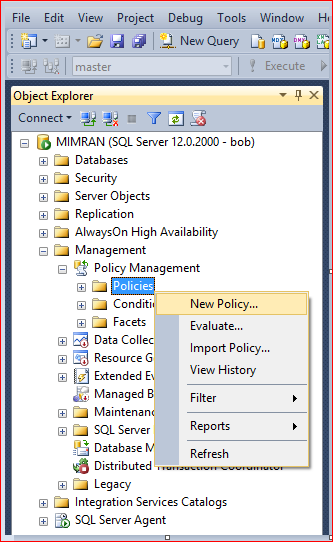
Step 5:
Now, we are in policy creation screen, here we need to give a proper Policy Name and then select the conditions created in Step 2 and Step 3 shown below in red and blue color border respectively. In other words, we are trying to make policy which checks the delayed durability is forced or NOT in all user databases which is online.
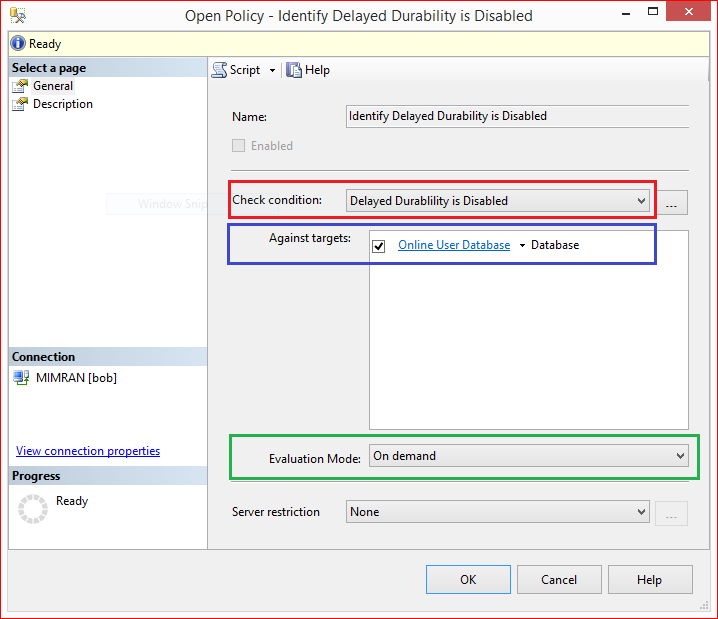
Usually I choose the Evaluation Mode to “On Demand” showing above because it is the easiest way to evaluate and fix any discrepancy across the databases / servers, however, you can select On Schedule as well and Press OK.
Step 6:
Now, the policy has been created and you can see it under policies as shown below. Just right click on and select Evaluate to evaluate the policy as shown below.
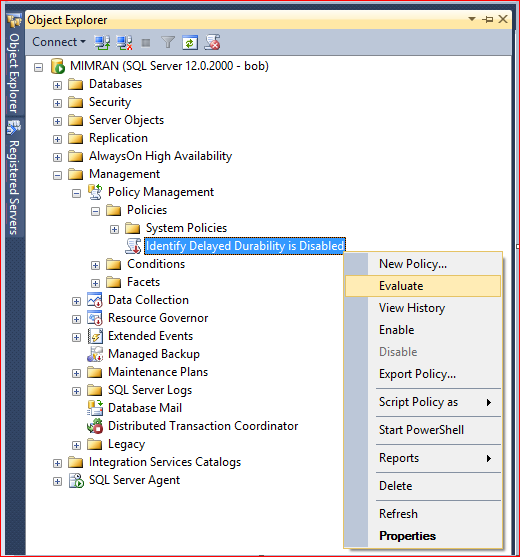
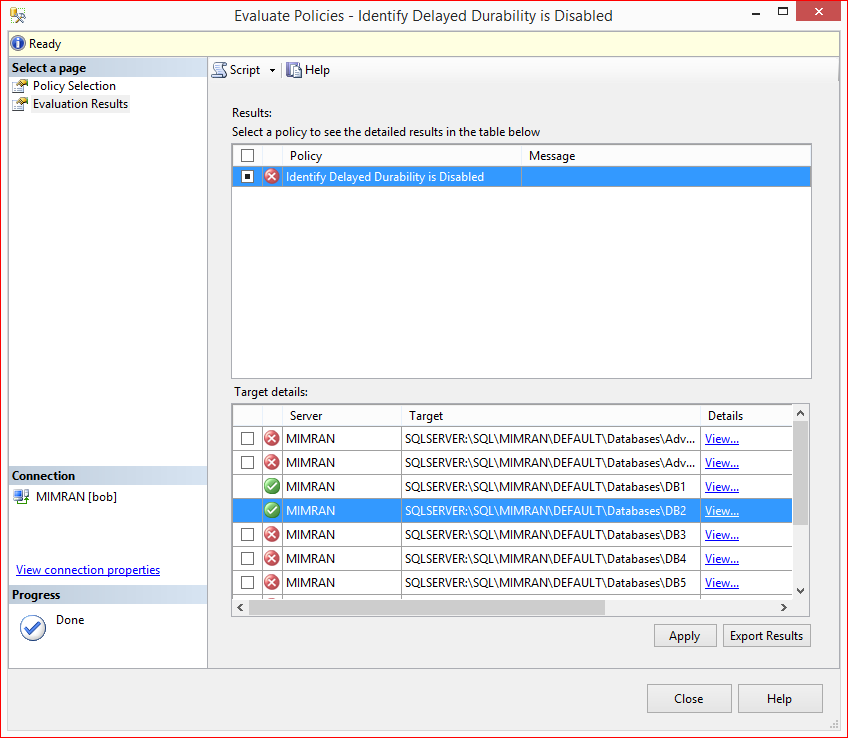
Step 7:
You are in evaluation screen and you can see all the user databases shows in red color because none of them is having database settings to delayed durability= force.
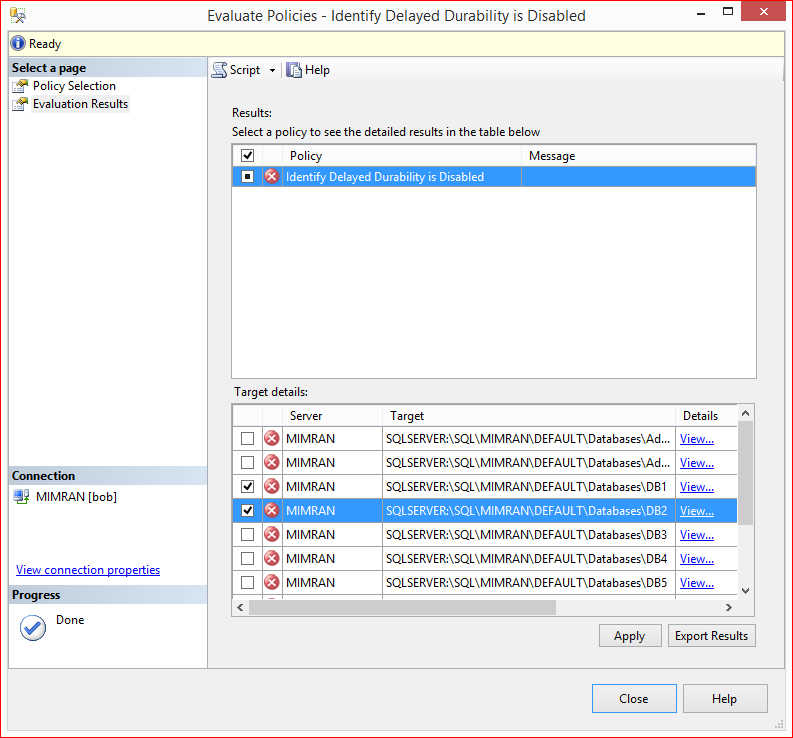
Step 8:
Lets click on View Details to see the difference in database settings as shown below. You can see that Policy is expecting the Delayed durability = force but the actual value is disabled.

Step 9:
Lets select the databases where you want to change the database settings of delayed durability to FORCE and press Apply button. It gives the given below messages. Press YES button.
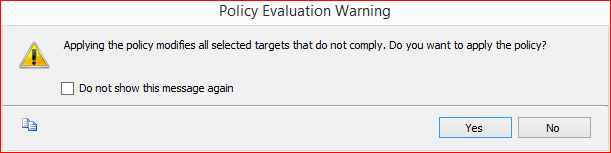
Step 10:
Once the policy has been implemented, policy based management will automatically evaluate the policy again and shows as green color icon as shown below.
Let me know if you have implemented any databases / servers settings using Policy Based Management.