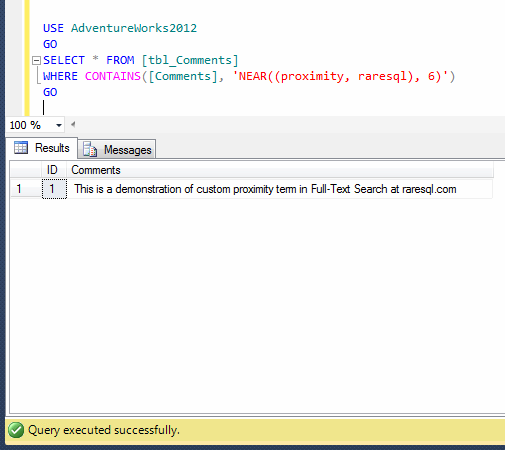
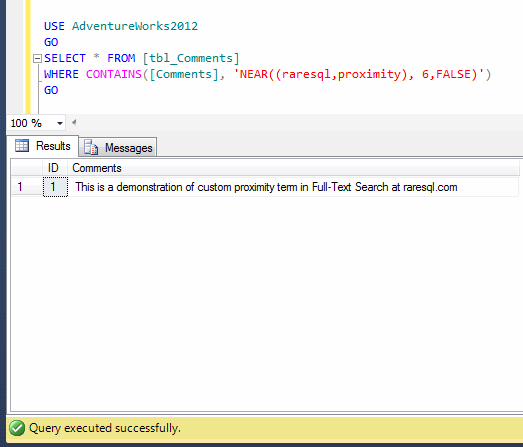
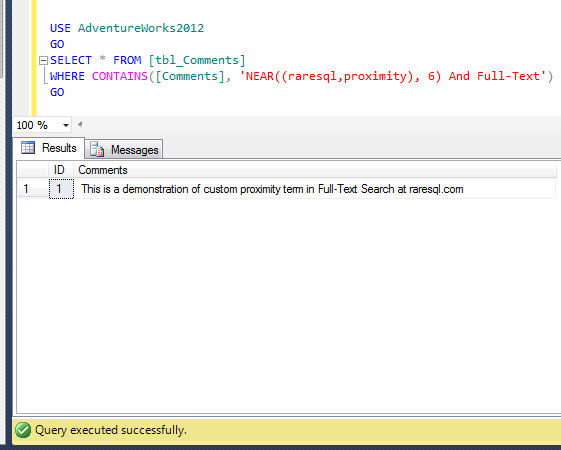
Columnstore index is one of the new features shipped with SQL Server 2012. I have written few articles about this type of index and described how it boosts in the performance. Recently, I worked on a huge table having table partitions residing in different file groups. And it seems that it is already optimized using Table partition. However, I tried to create a columnstore Index to further boost its performance and I did succeed.
Let me demonstrate it step by step.
Step 1 :
First of all, you need to create a partition function as shown below. If you already have partition function please SKIP this step.
USE AdventureWorks2012 GO CREATE PARTITION FUNCTION [PFByDueDate](datetime) AS RANGE RIGHT FOR VALUES ( N'2005-05-31T00:00:00', N'2006-05-31T00:00:00' , N'2007-05-31T00:00:00', N'2008-05-31T00:00:00' , N'2009-05-31T00:00:00' ) GO
Step 2 :
Secondly, you need to create a partition scheme on the above partition function as shown below. If you already have partition scheme please SKIP this step.
USE AdventureWorks2012 GO CREATE PARTITION SCHEME [PSDueDateByMonthRange] AS PARTITION [PFByDueDate] ALL TO ([PRIMARY]) GO
Step 3 :
Now, it is time to create a table using above created partition scheme to partition the data accordingly as shown below. If you already created a table using partition scheme please SKIP this step.
USE AdventureWorks2012 GO CREATE TABLE dbo.[PurchaseOrderDetail_Sample] ( [PurchaseOrderID] [int] NOT NULL, [PurchaseOrderDetailID] [int] NOT NULL, [DueDate] [datetime] NOT NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [LineTotal] numeric(18,2), [ReceivedQty] [decimal](8, 2) NOT NULL, [RejectedQty] [decimal](8, 2) NOT NULL, [StockedQty] Numeric(18,2), [ModifiedDate] [datetime] NOT NULL ) ON [PSDueDateByMonthRange]([DueDate]); GO
Step 4 :
Lets insert some data to test the performance.
--This query may take 2 to 10 minutes depends upon the server. USE AdventureWorks2012 GO INSERT INTO dbo.[PurchaseOrderDetail_Sample] WITH(TABLOCK) SELECT * FROM [Purchasing].[PurchaseOrderDetail] GO 100
Step 5 :
Once you insert the data, lets build the columnstore index. Remember, once you build the columnstore index you cannot modify the data in the table.
USE AdventureWorks2012 GO CREATE NONCLUSTERED COLUMNSTORE INDEX [IX_PurchaseOrderDetail_Sample_ColumnStore] ON [PurchaseOrderDetail_Sample] ( UnitPrice, OrderQty, ReceivedQty, ProductID) GO
Step 6 :
Once you build the columnstore index, lets execute the query and view the result set WITHOUT columnstore index.
--This query will ignore columnstore index --By using table's option namely IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX --and will return the result set. USE AdventureWorks2012 GO SET STATISTICS TIME ON SET STATISTICS IO ON GO SELECT ProductID as [Product ID] , AVG(UnitPrice) as [Average Unit Price] , SUM(OrderQty) as [Purchase Order Qty] , AVG(ReceivedQty) as [Received Qty] FROM [dbo].[PurchaseOrderDetail_Sample] WHERE [DueDate] Between '2007-01-01' And '2008-12-31' GROUP BY ProductID ORDER BY ProductID OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) GO --OUTPUT
SQL Server parse and compile time:
CPU time = 15 ms, elapsed time = 69 ms.
(265 row(s) affected)
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘PurchaseOrderDetail_Sample’. Scan count 3, logical reads 4100, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 983 ms, elapsed time = 1158 ms.
Step 7 :
Lets execute the query and view the result set WITH the columnstore index.
USE AdventureWorks2012 GO SET STATISTICS TIME ON SET STATISTICS IO ON GO SELECT ProductID as [Product ID] , AVG(UnitPrice) as [Average Unit Price] , SUM(OrderQty) as [Purchase Order Qty] , AVG(ReceivedQty) as [Received Qty] FROM [dbo].[PurchaseOrderDetail_Sample] WHERE [DueDate] Between '2007-01-01' And '2008-12-31' GROUP BY ProductID ORDER BY ProductID GO --OUTPUT
SQL Server parse and compile time:
CPU time = 16 ms, elapsed time = 57 ms.
(271 row(s) affected)
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘PurchaseOrderDetail_Sample’. Scan count 1, logical reads 242, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 717 ms, elapsed time = 782 ms.
Conclusion :
As you can observe, there is huge difference between both queries (with and without columnstore index) performance. However, you need to test it in your scenario and implement it accordingly. In addition, kindly read the restrictions & limitation about columnstore index as well.