WeatherAPI provides an API to get Weather condition of any location. In this article, we will use this API in SQL Server in order to get weather conditions of any location.
Let me explain it step by step.
Step 1:
Please Sign Up in WeatherAPI and create an account as shown below.
Step 2:
After Sign Up, login to the account, created in Step 1, it will direct to the screen where you can find your API key as shown below, please make a note of this Key.
Step 3:
You need to run given below script to enable OLE Automation Procedures. This is a prerequisite for next step.
sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
sp_configure 'Ole Automation Procedures', 1;
GO
RECONFIGURE;
GO
Step 4:
Let’s create given below stored procedure which takes location as an input and provides weather condition of that location.
USE tempdb
GO
CREATE OR ALTER PROCEDURE sp_Weather_Details
@Location NVARCHAR(250)
AS
DECLARE @URL NVARCHAR(250) = 'https://api.weatherapi.com/v1/current.json';
DECLARE @key VARCHAR(250) ='xxxxxxxxxxxxxxxxxxxxxxxxx'; --Enter your own API Key generated in Step 2
DECLARE @ConsolidatedURL NVARCHAR(250) = CONCAT(@URL,'?key=',@Key,'&q=',@location,'&aqi=no');
DECLARE @Object INT;
DECLARE @Json TABLE(DATA NVARCHAR(MAX));
DECLARE @ResponseText NVARCHAR(MAX);
EXEC sp_OACreate 'MSXML2.XMLHTTP', @Object OUT;
EXEC sp_OAMethod @Object, 'OPEN', NULL, 'GET', @ConsolidatedURL, 'FALSE';
EXEC sp_OAMethod @Object, 'SEND';
EXEC sp_OAMethod @Object, 'RESPONSETEXT', @ResponseText OUTPUT , @Json OUTPUT;
INSERT INTO @Json exec sp_OAGetProperty @Object, 'RESPONSETEXT';
DECLARE @Data NVARCHAR(MAX) = (SELECT DATA FROM @Json);
SELECT * FROM OPENJSON(@Data)
WITH
(
[Country] NVARCHAR(500) '$.location.country',
[Region] NVARCHAR(500) '$.location.region',
[City] NVARCHAR(500) '$.location.name',
[Current Temprature] NUMERIC(18,1) '$.current.temp_c',
[Humidity] NUMERIC(18,1) '$.current.humidity',
[Weather Condition] NVARCHAR(500) '$.current.condition.text',
[Wind Speed] NUMERIC(18,1) '$.current.wind_kph'
);
GO
Let’s run few examples and see the weather conditions.
Example 1:
Location: Karachi, Pakistan
USE tempdb
GO
EXEC sp_Weather_Details 'Karachi';
GO
Example 2:
Location: Dubai, UAE
USE tempdb
GO
EXEC sp_Weather_Details 'Dubai';
GO
Example 3:
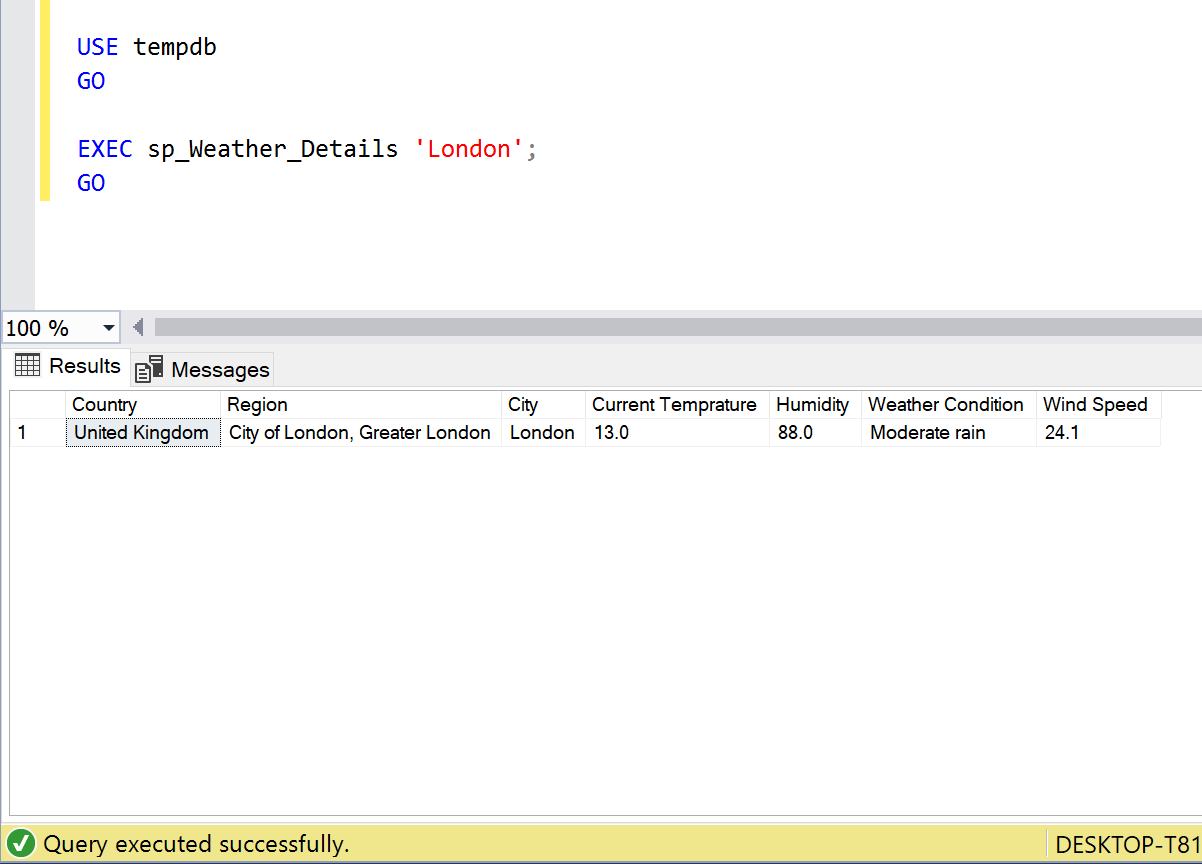
Location: London, UK
USE tempdb
GO
EXEC sp_Weather_Details 'London';
GO
Example 4:
Location: New York, USA
USE tempdb
GO
EXEC sp_Weather_Details 'New York';
GO
Conclusion:
I found this API very useful whenever I need to find the weather of any location. Do let me know your feedback.
Google translate provides API to translate text from one language to another. In this article, we will use this API in SQL Server and translate some text. Please sign up in google translate and create an account which provides you the Key. Please use this Key in the given below stored procedure.
Before creating the stored procedure, you need to run given below script to enable Ole Automation Procedures. This is a prerequisite for the given below solution.
Enable OLE Automation procedures:
sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
sp_configure 'Ole Automation Procedures', 1;
GO
RECONFIGURE;
GO
Solution:
USE tempdb
GO
CREATE OR ALTER PROCEDURE sp_translate_text
@TextToBeTranslated NVARCHAR(500),
@SourceLanguage NVARCHAR(50),
@TargetLanguage NVARCHAR(50),
@Key NVARCHAR(250) = 'Please use Translate API key provided by google'
AS
DECLARE @URL NVARCHAR(250) = 'https://translation.googleapis.com/language/translate/v2';
DECLARE @ConsolidatedURL NVARCHAR(250) = CONCAT(@URL,'?key=',@Key);
DECLARE @Object INT;
DECLARE @Json TABLE(DATA NVARCHAR(MAX));
DECLARE @ResponseText NVARCHAR(MAX);
DECLARE @Body NVARCHAR(MAX) = CONCAT('{','"q":','"',@TextToBeTranslated,'"',',','"target":','"',@TargetLanguage,'"',',','"source":','"',@SourceLanguage,'"','}');
EXEC sp_OACreate 'MSXML2.XMLHTTP', @Object OUT;
EXEC sp_OAMethod @Object, 'OPEN', NULL, 'POST', @ConsolidatedURL, 'FALSE';
EXEC sp_OAMethod @Object, 'SETREQUESTHEADER', NULL, 'CONTENT-TYPE', 'APPLICATION/JSON';
EXEC sp_OAMethod @Object, 'SEND', NULL, @Body;
EXEC sp_OAMethod @Object, 'RESPONSETEXT', @ResponseText OUTPUT , @Json OUTPUT;
INSERT INTO @Json exec sp_OAGetProperty @Object, 'RESPONSETEXT';
DECLARE @Data NVARCHAR(MAX) = (SELECT DATA FROM @Json);
SELECT @SourceLanguage AS [Source Language]
, @TargetLanguage AS [Target Language]
, TranslatedText AS [Translated Text]
FROM OPENJSON(@Data,'$.data.translations')
WITH
(
[TranslatedText] NVARCHAR(500) '$.translatedText'
);
GO
Example 1:
Text to be translated: “How are you”
Source Language: English
Target Language: Urdu
USE tempdb
GO
EXEC sp_translate_text N'how are you','en','ur';
GO
Example 2:
Text to be translated: “آپ کیسے ہو”
Source Language: Urdu
Target Language: English
USE tempdb
GO
EXEC sp_translate_text N'آپ کیسے ہو','ur','en';
GO
Example 3:
Text to be translated: “How are you”
Source Language: English
Target Language: Arabic
USE tempdb
GO
EXEC sp_translate_text N'how are you','en','ar';
GO
Example 4:
Text to be translated: “كيف حالكم”
Source Language: Arabic
Target Language: English
USE tempdb
GO
EXEC sp_translate_text N'كيف حالكم','ar','en';
GO
Example 5:
Text to be translated: “How are you”
Source Language: English
Target Language: Hindi
USE tempdb
GO
EXEC sp_translate_text N'how are you','en','hi';
GO
Example 6:
Text to be translated: “आप कैसे हैं”
Source Language: Hindi
Target Language: English
USE tempdb
GO
EXEC sp_translate_text N'आप कैसे हैं','hi','en';
GO
Conclusion:
I found Google translate API very useful whenever I need to convert any text from one language to another. It works very smoothly. Do let me know if you use it and how did you find it.
Comparing files is one of the frequent activities, when we want to see the difference between two files. SQL developers face this problem on a day to day basis when they have two versions of the same file and they want to know where they made changes.
Fortunately, SQL Server Management Studio (SSMS) has this toolbar, which you can use to compare two files very easily.
In order to explain it, let me create two scripts as shown below.
Sample:
The below scripts will be saved as Version1.sql & Version2.sql.
Version1:
USE Northwind
GO
CREATE OR ALTER VIEW [dbo].[OrdersQry]
AS
SELECT Orders.OrderID
, Orders.ShipName AS ShipName
FROM Customers
INNER JOIN Orders
ON Customers.CustomerID = Orders.CustomerID;
GO
Version2:
USE Northwind
GO
CREATE OR ALTER VIEW [dbo].[OrdersQry]
AS
SELECT COUNT(Orders.OrderID) AS TotalOrders
, Orders.ShipName AS ShipName
, Orders.ShipAddress AS ShipAddress
FROM Customers
INNER JOIN Orders
ON Customers.CustomerID = Orders.CustomerID
GROUP BY Orders.ShipName
, Orders.ShipAddress;
GO
Now, let’s compare above mentioned both scripts (Version1.sql, Version2.sql) in SQL Server Management Studio (SSMS) as shown in below steps.
Step 1:
Let’s activate Compare Files toolbar by clicking on View menu then click on Toolbars, and in Toolbars, click on Compare Files option as shown below.
The Compare Files toolbar will appear as shown below.
Step 2:
In the toolbar, there is menu button on extreme left hand side which shows the mode of compare. We have 4 types of mode as described below.
Side-by-side mode: It compares both files side by side. This is selected by default as shown below.
Inline mode: It compares combined scripts.
Left file only: It compares the first script.
Right file only: It compares the second file only.
Step 3:
Open File Version1 and Version2 in SQL Server Management Studio (SSMS) as shown below.
Step 4:
Open Command Widow by clicking on View menu then click on Other Windows then select Command Widow Or use shortcut(Ctrl+Alt+A).
Step 5:
In the Command Window, type Command Tools.DiffFiles and give the file name (Version1.sql, Version2.sql) which needs to be compared and press Enter as shown below.
Tools.DiffFiles Version1.sql Version2.sql
Step 6:
Both files will be compared in side by side mode since it is selected by default and the output will be as shown below.
Additional scripts in the second file (Version2.sql) are represented in GREEN color.
Modified or deleted scripts from first file (Version1.sql) are represented in RED color.
Scripts which are NOT changed are represented in NO Background color.
Please note that in case of any changes which are made to these files need to be saved again, we need to run the DiffFiles command again.
Conclusion:
Compare Files toolbar is one of the handy toolbars in SQL Server Management Studio (SSMS). Do let me know if you use it and found it helpful.
Sometimes, we come across a situation where the transaction log file grows unexpectedly, and it needs to be managed properly. One of the options is to reduce the size of database transaction log by shrinking the database transaction log file. Please be careful while implementing this solution on production databases.
Let me create a sample and then expalin it step by step as shown below.
Sample:
CREATE DATABASE SampleDB;
GO
Use SampleDB
GO
CREATE TABLE [Customers]
(
[CustomerID] INT IDENTITY(1,1),
[CustomerName] VARCHAR(250),
[RegistrationDate] DATE,
[EmailAddress] VARCHAR(100),
[Address] VARCHAR(500),
[PhoneNumber] VARCHAR(100)
);
GO
--Lets's insert 3,000,000 records in customer table
INSERT INTO [Customers]
(CustomerName,RegistrationDate,EmailAddress,Address,PhoneNumber)
VALUES('John','01-13-2023','John@raresql.com','AB Street','0134018201');
GO 3000000
Step 1:
Let’s check the size of the database files as shown below.
Use SampleDB
GO
SELECT name AS [DB File Name]
, size AS [Size in KBs]
, size * 8/1024 AS [Size in MBs]
, Max_Size AS [Max Size]
FROM sys.master_files
WHERE DB_NAME(database_id) = 'SampleDB';
GO
Step 2:
Now, let’s take the full backup of the database by using the following query.
--Backup database
BACKUP DATABASE [SampleDB] TO DISK = N'D:\SampleDB_Backup.bak';
GO
Step 3:
Let’s shrink database log file by using the following script.
Use SampleDB
GO
--Let's change recovery model to simple
ALTER DATABASE SampleDB
SET RECOVERY SIMPLE;
GO
--Let's shrink the database log file
DBCC SHRINKFILE (SampleDB_log, 1, TRUNCATEONLY);
GO
--Let's change recovery model to full
ALTER DATABASE SampleDB
SET RECOVERY FULL;
GO
Step 4:
Let’s check the database log file size again. As we can see below the database_log file size has been reduced.
Use SampleDB
GO
SELECT name AS [DB File Name]
, size AS [Size in KBs]
, size * 8/1024 AS [Size in MBs]
, Max_Size AS [Max Size]
FROM sys.master_files
WHERE DB_NAME(database_id) = 'SampleDB';
GO
Conclusion:
This is one of easiest ways to shrink the database transation log. Do let me know, which method you use and how effective it is.
All of us are familiar with Common Table Expression (CTE) because of its frequent use. We use it in our day-to-day operation quite frequently. Recently, I came across a case where I had to use CTE in a user defined function.
Let me create a sample user defined function (UDF) in Northwind database with the help of CTE to use in my demonstration as shown below.
USE Northwind
GO
CREATE FUNCTION [dbo].[udf_Most_Expensive_Product]
(
@SupplierID INT
)
RETURNS NVARCHAR(50)
AS
BEGIN
DECLARE @ProductName NVARCHAR(50)
;WITH CTE AS
(
SELECT ROW_NUMBER() OVER (ORDER BY UnitPrice DESC) AS SNo
, ProductName
, UnitPrice FROM Products
WHERE SupplierID = @SupplierID
)
SELECT
@ProductName = ProductName
FROM CTE
WHERE SNo = 1
RETURN @ProductName;
END
GO
Let me call the above created user defined function(UDF) and see the results.
USE Northwind
GO
SELECT [dbo].[udf_Most_Expensive_Product](2) AS [ProductName];
GO
--OUTPUT
Conclusion:
It is quite simple to use Common Table Expression (CTE) in user defined function (UDF).
In SQL Server 2022, an enhancement came in RTRIM() function, which was a long awaited functionality. This enhancement helps us to remove last character from the string. I have written an article about it in detail.
Recently, I was using RTRIM() function and came across an error as mentioned below.
Error:
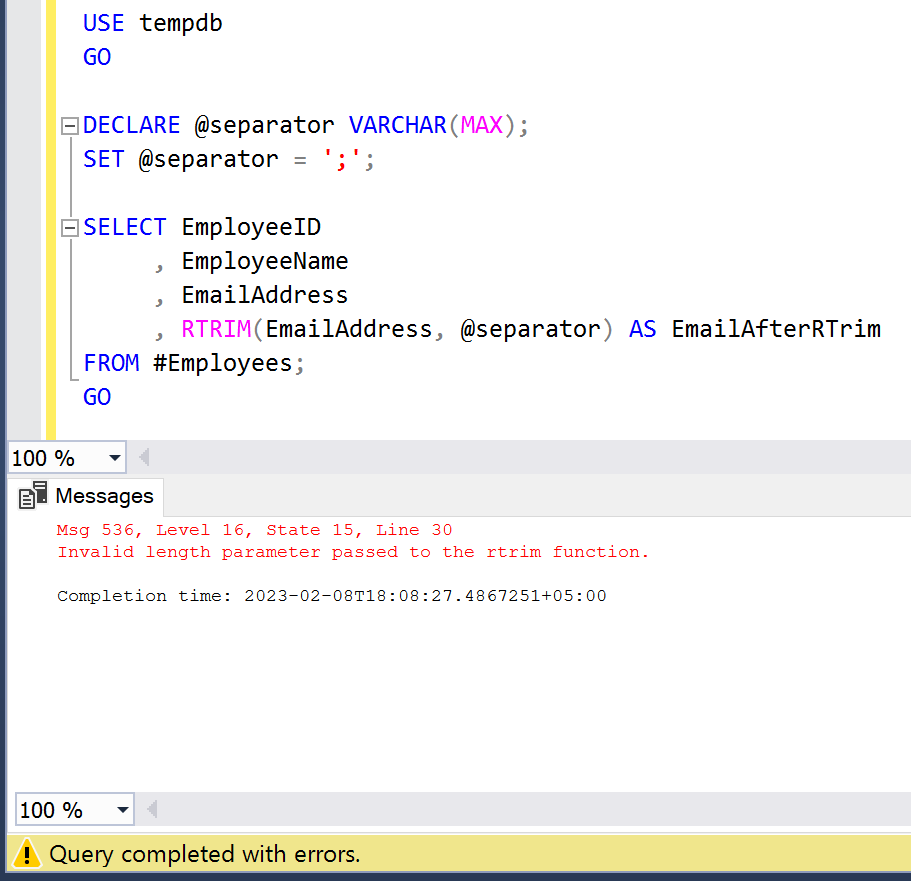
Invalid length parameter passed to the rtrim function.
Sample:
USE tempdb
GO
CREATE TABLE #Employees
(
EmployeeID INT IDENTITY(1,1),
EmployeeName VARCHAR(250),
EmailAddress VARCHAR(MAX)
);
GO
INSERT INTO #Employees
VALUES ('Alex','alex114@gmail.com;')
, ('Sarina','sarina152@gmail.com;')
, ('Sophia','sophiaa123@gmail.com;');
GO
SELECT * FROM #Employees;
GO
Example:
In the given below example, I have written a simple script using RTRIM() function and I declared separator as variable and kept its data type & length as VARCHAR(MAX). This script generates an error as shown below.
USE tempdb
GO
DECLARE @separator VARCHAR(MAX);
SET @separator = ';';
SELECT EmployeeID
, EmployeeName
, EmailAddress
, RTRIM(EmailAddress, @separator) AS EmailAfterRTrim
FROM #Employees;
GO
Solution:
The solution to this problem is that while declaring datatype and length of a separator variable, we should never use MAX as its length since it does not support. We should always give length in numbers as shown below.
USE tempdb
GO
DECLARE @separator VARCHAR(1);
SET @separator = ';';
SELECT EmployeeID
, EmployeeName
, EmailAddress
, RTRIM(EmailAddress, @separator) AS EmailAfterRTrim
FROM #Employees;
GO
Conclusion:
Whenever you use RTRIM() function by using a separator variable, you should always define the length of the variable. Please don’t use MAX as a length to avoid such error.
In SQL Server 2022, an enhancement came in LTRIM() function, which was a long awaited enhancement. This enhancement helps us to remove first character from the string. I have written an article about it in detail.
Recently, I was using LTRIM() function and came across an error as mentioned below.
Error:
Invalid length parameter passed to the ltrim function.
Sample:
USE tempdb
GO
CREATE TABLE #Employees
(
EmployeeID INT IDENTITY(1,1),
EmployeeName VARCHAR(250),
EmailAddress VARCHAR(MAX)
);
GO
INSERT INTO #Employees
VALUES ('Alex','alex114@gmail.com;')
, ('Sarina','sarina152@gmail.com;')
, ('Sophia','sophiaa123@gmail.com;');
GO
SELECT * FROM #Employees;
GO
Example:
In the given below example, I have written a simple script using LTRIM() function and I declared separator as variable and kept its data type & length as VARCHAR(MAX). This script generates an error as shown below.
USE tempdb
GO
DECLARE @separator VARCHAR(MAX);
SET @separator = ';';
SELECT EmployeeID
, EmployeeName
, EmailAddress
, LTRIM(EmailAddress, @separator) AS EmailAfterLTrim
FROM #Employees;
GO
Solution:
The solution to this problem is that while declaring datatype and length of a separator variable, we should never use MAX as its length since it does not support. We should always give length in numbers as shown below.
USE tempdb
GO
DECLARE @separator VARCHAR(1);
SET @separator = ';';
SELECT EmployeeID
, EmployeeName
, EmailAddress
, LTRIM(EmailAddress, @separator) AS EmailAfterLTrim
FROM #Employees;
GO
Conclusion:
Whenever you use LTRIM() function by using a separator variable, you should always define the length of the variable. Please don’t use MAX as a length to avoid such error.
In SQL Server 2022, an enhancement came in TRIM() function which was a long awaited functionality. This enhancement helps us in removing first or last character from the string. I have written an article about it in detail.
Recently, I was using TRIM() function and came across an error as mentioned below.
Error:
Invalid length parameter passed to the trim function.
Sample:
USE tempdb
GO
CREATE TABLE #Employees
(
EmployeeID INT IDENTITY(1,1),
EmployeeName VARCHAR(250),
EmailAddress VARCHAR(MAX)
);
GO
INSERT INTO #Employees
VALUES ('Alex','alex114@gmail.com;')
, ('Sarina','sarina152@gmail.com;')
, ('Sophia','sophiaa123@gmail.com;');
GO
SELECT * FROM #Employees;
GO
Example:
In the given below example, I have written a simple script using TRIM() function and I declared separator as variable and kept its data type & length as VARCHAR(MAX). This script generates an error as shown below.
DECLARE @separator VARCHAR(MAX);
SET @separator = ';';
SELECT EmployeeID
, EmployeeName
, EmailAddress
, TRIM(@separator FROM EmailAddress) AS EmailAfterTrim
FROM #Employees;
GO
Solution:
The solution to this problem is that while declaring datatype and length of a separator variable, we should never use MAX as its length since it does not support. We should always give length in numbers as shown below.
DECLARE @separator VARCHAR(1);
SET @separator = ';';
SELECT EmployeeID
, EmployeeName
, EmailAddress
, TRIM(@separator FROM EmailAddress) AS EmailAfterTrim
FROM #Employees;
GO
Conclusion:
Whenever you use TRIM() function by using a separator variable, you should always define the length of the variable. Please don’t use MAX as a length in order to avoid such error.
SQL Server 2022brought some exciting features which will help us in optimising the SQL scripts. IS [NOT] DISTINCT FROM is one of the new features. It helps us in code optimisation and reduce the code complexity.
Compatibility Level:
Your database compatibility level MUST be 160 or higher to use this new feature.
ALTER DATABASE tempdb SET COMPATIBILITY_LEVEL = 160
Sample:
USE tempdb
GO
CREATE TABLE [#Customer](
[CustomerID] INT IDENTITY(1,1),
[CustomerName] VARCHAR(100),
[PhoneNumber] VARCHAR(100),
[AlternatePhoneNumber] VARCHAR(100));
GO
INSERT INTO [#Customer]
([CustomerName],[PhoneNumber],[AlternatePhoneNumber])
VALUES
('Maria','+92-300074321','+92-300074321'),
('Trujillo',null,null),
('Antonio','+96-562108460',null),
('Thomas',null,'+96-0515552282'),
('Christina','+92-059675428','+92-05676753425');
GO
SELECT * FROM [#Customer];
GO
--OUTPUT
Example 1:
IS DISTINCT FROM
Old Approach:(Using Complex WHERE Clause)
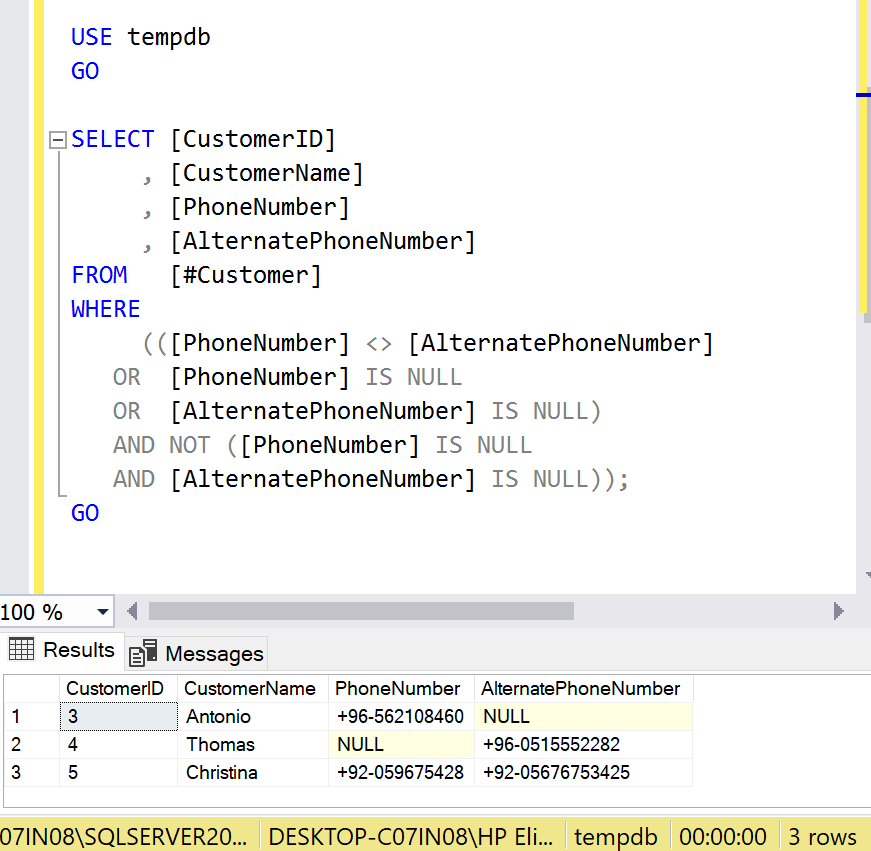
Whenever we need to search some records having NULL, the search criteria will look like this.
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
WHERE
(([PhoneNumber] <> [AlternatePhoneNumber]
OR [PhoneNumber] IS NULL
OR [AlternatePhoneNumber] IS NULL)
AND NOT ([PhoneNumber] IS NULL
AND [AlternatePhoneNumber] IS NULL));
GO
--OUTPUT
New Approach:(Using IS DISTINCT FROM)
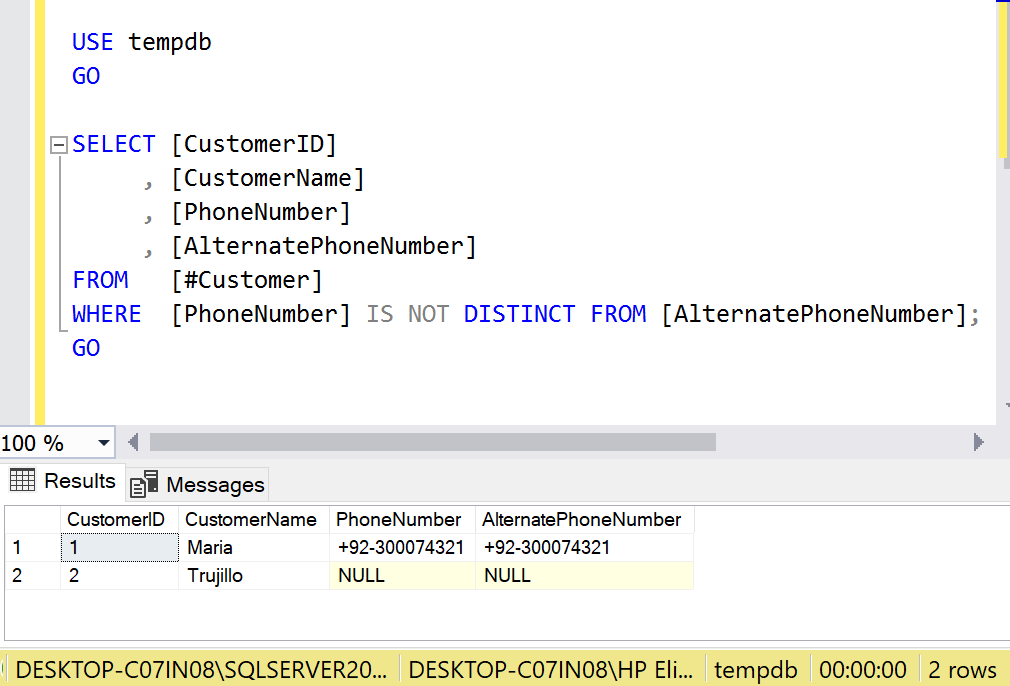
The complexity and length of where clause has been reduced by the new enhancement which comes with the name IS DISTINCT FROM which takes all unique records of two columns as well as return single null values and drop where both columns are null as shown below:
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
WHERE [PhoneNumber] IS DISTINCT FROM [AlternatePhoneNumber];
GO
--OUTPUT
Example 2:
IS NOT DISTINCT FROM
Old Approach:(Using Complex WHERE Clause)
In old methodology if we had to take same values from two columns and also where both columns have null values, then the query would be as shown below:
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
WHERE
(NOT ([PhoneNumber] <> [AlternatePhoneNumber]
OR [PhoneNumber] IS NULL
OR [AlternatePhoneNumber] IS NULL)
OR ([PhoneNumber] IS NULL
AND [AlternatePhoneNumber] IS NULL));
GO
--OUTPUT
New Approach:(Using IS NOT DISTINCT FROM)
In new Approach, the complexity has been reduced to just single clause named IS [NOT] DISTINCT FROM & rest all conditions are applied by default as shown in the picture below:
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
WHERE [PhoneNumber] IS NOT DISTINCT FROM [AlternatePhoneNumber];
GO
--OUTPUT
Example 3:
IS DISTINCT FROM
Old Approach:(Using Complex HAVING Clause)
In old methodology if we had to take unique values using HAVING Clause from two columns and also single null values and drop where both columns are null, then the query would be as shown below:
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
GROUP BY
[CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
HAVING
(([PhoneNumber] <> [AlternatePhoneNumber]
OR [PhoneNumber] IS NULL
OR [AlternatePhoneNumber] IS NULL)
AND NOT ([PhoneNumber] IS NULL
AND [AlternatePhoneNumber] IS NULL));
GO
--OUTPUT
New Approach:(Using IS DISTINCT FROM)
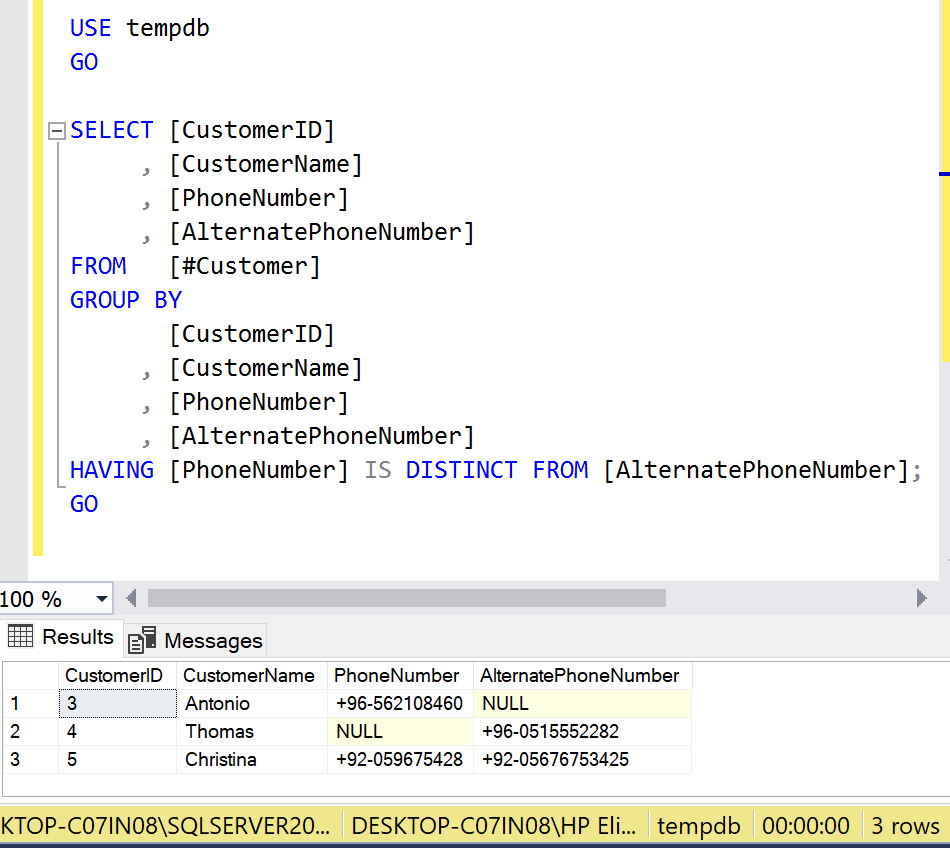
The complexity is being reduced by New Approach where we need to write only one clause and rest is handled by itself as shown in the example below.
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
GROUP BY
[CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
HAVING
[PhoneNumber] IS DISTINCT FROM [AlternatePhoneNumber];
GO
--OUTPUT
Example 4:
IS NOT DISTINCT FROM
Old Approach:(Using Complex HAVING Clause):
In old methodology if we had to take same values using HAVING from two columns and also where both columns have null values then the query would be as shown below.
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
GROUP BY
[CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
HAVING
(NOT ([PhoneNumber] [AlternatePhoneNumber]
OR [PhoneNumber] IS NULL
OR [AlternatePhoneNumber] IS NULL)
OR ([PhoneNumber] IS NULL
AND [AlternatePhoneNumber] IS NULL));
GO
--OUTPUT
New Approach:(Using IS NOT DISTINCT FROM)
The complexity is being reduced by New Approach where we need to write only one clause and rest is handled by itself as shown in the example below.
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
GROUP BY
[CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
HAVING [PhoneNumber] IS DISTINCT FROM [AlternatePhoneNumber];
GO
--OUTPUT
Conclusion:
The IS [NOT] DISTINCT Clause is a life saver where writing a query with multiple conditions just reduced to a single clause. It also reduces the complexity of the query. Do let me know if you used IS [NOT] DISTINCT Clause and found it useful.
In SQL Server 2022, a new enhancement was introduced in dynamic data masking known as Granular Permissions which was a long-awaited enhancement. This new enhancement gives us control to provide unmasking permission at lowest level (table’s column) which we could not achieve in the earlier version of SQL Server. In other words, we can give permissions to unmask columns, tables, schemas & databases to different users based on their accessibility levels.
Let me create a sample to demonstrate the functionality of Dynamic data masking granular permissions in which, I will create a Sample database, two schemas and each schema will have one table as shown below.
Sample:
--Create Sample Database
CREATE DATABASE SampleDB;
GO
USE SampleDB
GO
--Create HumanResources Schema
CREATE SCHEMA HumanResources;
GO
--Create Accounts Schema
CREATE SCHEMA Accounts;
GO
--Create Employee Table
CREATE TABLE HumanResources.Employee
(
EmployeeID INT IDENTITY(1,1) NOT NULL PRIMARY KEY,
EmployeeName VARCHAR(250),
Birthdate DATE MASKED WITH (FUNCTION = 'default()') NULL,
Salary DECIMAL(10,2) MASKED WITH (FUNCTION = 'default()') NULL
);
GO
--Create BankAccount Table
CREATE TABLE Accounts.BankAccount
(
AccountID INT IDENTITY(1,1) PRIMARY KEY,
EmployeeID INT NOT NULL,
AccountTitle VARCHAR(250) MASKED WITH (FUNCTION = 'default()') NULL,
AccountNumber VARCHAR(250) MASKED WITH (FUNCTION = 'partial(3,"xxxxxxxxx", 4)') NULL
);
GO
--Insert few records into Employee Table
INSERT INTO Humanresources.Employee(EmployeeName,Birthdate,Salary)
VALUES ('Nancy','1988-12-08','200000'),
('Andrew','1994-07-16','120000'),
('Janet','1994-07-16','75000');
GO
--Insert few records into BankAccount table
INSERT INTO Accounts.BankAccount(EmployeeID,AccountTitle,AccountNumber)
VALUES(1,'Nancy','9922-0105664197'),
(2,'Andrew','0010-0107605278'),
(3,'Janet','4010-3568743987');
GO
Configuration:
Step 1:
Let’s create few users, which will be used to provide relevant permissions to unmask data as shown below.
USE SampleDB
GO
--Create User HRAdministrator
CREATE USER HRAdministrator WITHOUT LOGIN;
GO
--Create User PayrollAdministrator
CREATE USER PayrollAdministrator WITHOUT LOGIN;
GO
--Create User Accountant
CREATE USER Accountant WITHOUT LOGIN;
GO
--Create User HRManager
CREATE USER HRManager WITHOUT LOGIN;
GO
Step 2:
Let’s add the db_datareader role in each user created above.
USE SampleDB
GO
--Grant db_datareader role to HRAdministrator
ALTER ROLE db_datareader ADD MEMBER HRAdministrator;
GO
--Grant db_datareader role to PayrollAdministrator
ALTER ROLE db_datareader ADD MEMBER PayrollAdministrator ;
GO
--Grant db_datareader role to Accountant
ALTER ROLE db_datareader ADD MEMBER Accountant;
GO
--Grant db_datareader role to HRManager
ALTER ROLE db_datareader ADD MEMBER HRManager;
GO
Step 3:
Let’s provide UNMASK permissions to above created users. The details of the access are as shown below:
HRAdministrator: can view Birthdate column Data only in Employee table.
PayrollAdministrator: can view Salary column Data only in Employee table .
Accountant : can view the entire tables data in Account schema only.
HRManager : can view the entire data in the SampleDB database.
USE SampleDB
GO
--Grant Birthday column unmask permission to HRAdministrator;
GRANT UNMASK ON Humanresources.Employee(Birthdate) TO HRAdministrator;
GO
--Grant salary column unmask permission to PayrollAdministrator
GRANT UNMASK ON Humanresources.Employee(Salary) TO PayrollAdministrator;
GO
--Grant Accounts schema unmask permission to Accountant
GRANT UNMASK ON SCHEMA::Accounts TO Accountant;
GO
--Grant entire database unmask permission to HRManager
GRANT UNMASK TO HRManager;
GO
Testing:
HRAdministrator
Let’s access the Employee table under the context of HRAdministrator user.
USE SampleDB
GO
EXECUTE AS USER='HRAdministrator';
SELECT EmployeeID
, EmployeeName
, Birthdate
, Salary
FROM Humanresources.Employee;
REVERT;
GO
--OUTPUT
As we can see above, the HRAdministrator can view the Birthdate column data in Employee table but cannot view Salary column data in Employee table.
Let’s access the BankAccount table under the context of HRAdministrator user.
USE SampleDB
GO
EXECUTE AS USER='HRAdministrator';
SELECT EmployeeID
, AccountTitle
, AccountNumber
FROM Accounts.BankAccount;
REVERT;
GO
--OUTPUT
As we can see above, the HRAdministrator can’t view the data of BankAccount Table since unmask permission is not given.
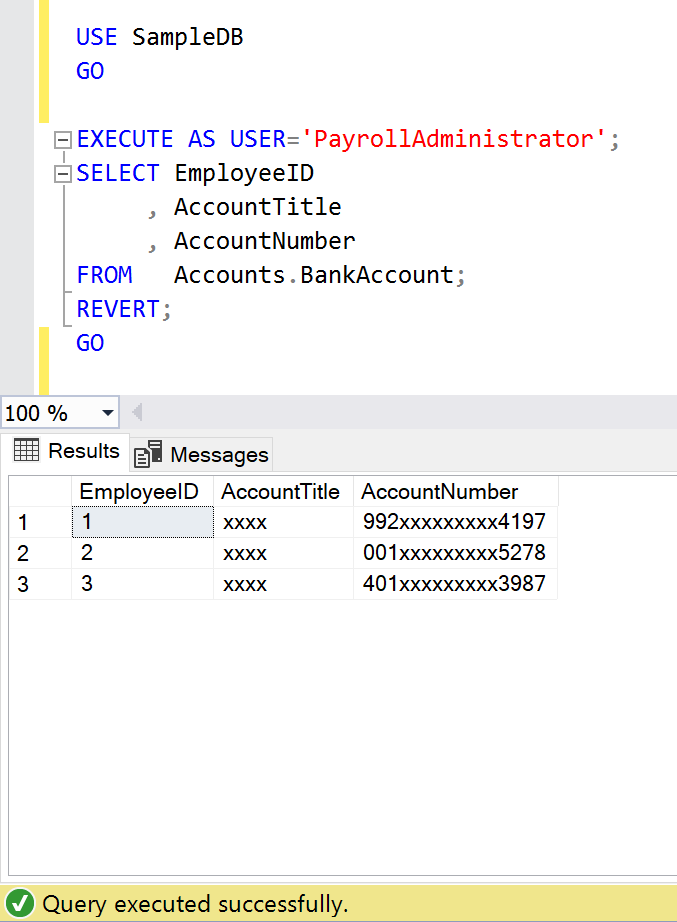
PayrollAdministrator
Let’s access Employee table under the context of PayrollAdministrator user.
USE SampleDB
GO
EXECUTE AS USER='PayrollAdministrator';
SELECT EmployeeID
, EmployeeName
, Birthdate
, Salary
FROM Humanresources.Employee;
REVERT;
GO
--OUTPUT
As we can see above, the PayrollAdministrator can view the Salary column data in Employee table but cannot view Birthdate column data in Employee table.
Let’s access the BankAccount table under the context of PayrollAdministrator user.
USE SampleDB
GO
EXECUTE AS USER='PayrollAdministrator';
SELECT EmployeeID
, AccountTitle
, AccountNumber
FROM Accounts.BankAccount;
REVERT;
GO
--OUTPUT
As we can see above, the PayrollAdministrator can’t view the data of BankAccount Table since unmask permission is not given.
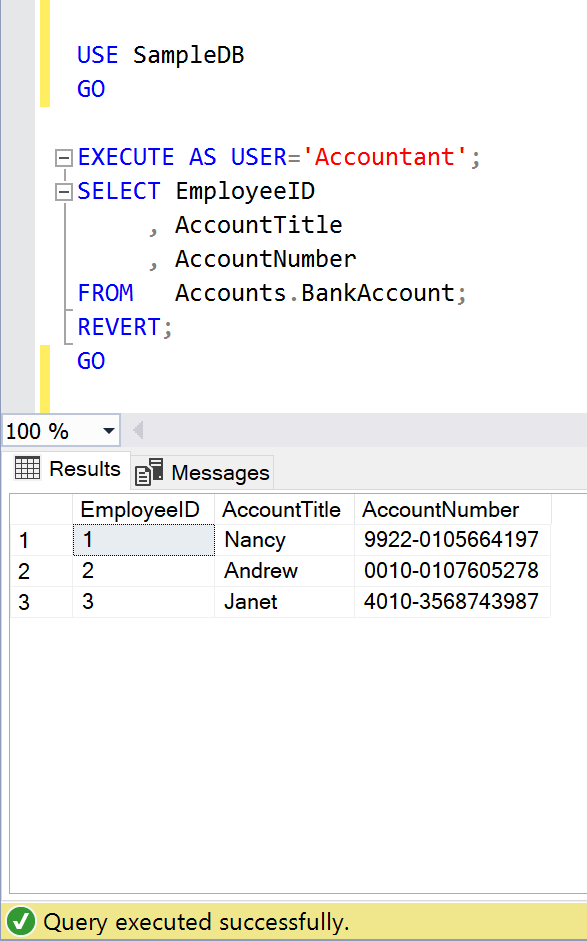
Let’s access the Employee table under the context of Accountant user.
USE SampleDB
GO
EXECUTE AS USER='Accountant';
SELECT EmployeeID
, EmployeeName
, Birthdate
, Salary
FROM Humanresources.Employee;
REVERT;
GO
--OUTPUT
As we can see above, the Accountant cannot view the Salary, Birthdate column data in Employee table since unmask permission is not given.
Let’s access the BankAccount table which is in Accounts schema under the context of Accountant user.
USE SampleDB
GO
EXECUTE AS USER='Accountant';
SELECT EmployeeID
, AccountTitle
, AccountNumber
FROM Accounts.BankAccount;
REVERT;
GO
--OUTPUT
As we can see above, the Accountant can view the data of BankAccount Table.
Let’s access the Employee table which is in HumanResources schema under the context of HRManager user.
USE SampleDB
GO
EXECUTE AS USER='HRManager';
SELECT EmployeeID
, EmployeeName
, Birthdate
, Salary
FROM Humanresources.Employee;
REVERT;
GO
--OUTPUT
As we can see above, the HRManager can view the data of Employee Table.
Let’s access the BankAccount table which is in Accounts schema under the context of HRManager user.
USE SampleDB
GO
EXECUTE AS USER='HRManager';
SELECT EmployeeID
, AccountTitle
, AccountNumber
FROM Accounts.BankAccount;
REVERT;
GO
--OUTPUT
As we can see above, the HRManager can view the data of BankAccount Table.
Conclusion:
Granular Permission in dynamic data masking is a very handy enhancement, it gives us the control to unmask column, table, schema, database data to different users. Do let me know if you use it and found it helpful.
This blog/website is a personal blog/website and all articles, postings and opinions contained herein are my own. The contents of this blog/website are not intended to defame, purge or humiliate anyone should they decide to act upon or reuse any information provided by me. Comments left by any independent reader are the sole responsibility of that person. Should you identify any content that is harmful, malicious, sensitive or unnecessary, please contact me via email (imran@raresql.com) so I may rectify the problem.