SQL Server 2022 brought some exciting features which will help us in optimising the SQL scripts. IS [NOT] DISTINCT FROM is one of the new features. It helps us in code optimisation and reduce the code complexity.
Compatibility Level:
Your database compatibility level MUST be 160 or higher to use this new feature.
ALTER DATABASE tempdb SET COMPATIBILITY_LEVEL = 160
Sample:
USE tempdb
GO
CREATE TABLE [#Customer](
[CustomerID] INT IDENTITY(1,1),
[CustomerName] VARCHAR(100),
[PhoneNumber] VARCHAR(100),
[AlternatePhoneNumber] VARCHAR(100));
GO
INSERT INTO [#Customer]
([CustomerName],[PhoneNumber],[AlternatePhoneNumber])
VALUES
('Maria','+92-300074321','+92-300074321'),
('Trujillo',null,null),
('Antonio','+96-562108460',null),
('Thomas',null,'+96-0515552282'),
('Christina','+92-059675428','+92-05676753425');
GO
SELECT * FROM [#Customer];
GO
--OUTPUT

Example 1:
- IS DISTINCT FROM
Whenever we need to search some records having NULL, the search criteria will look like this.
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
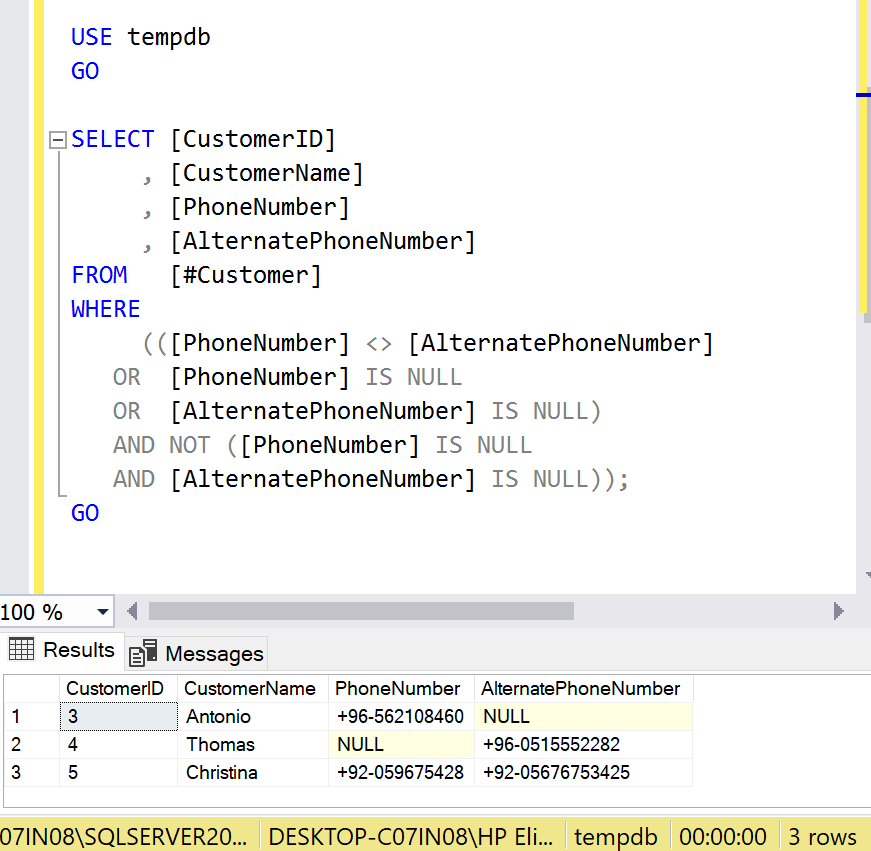
WHERE
(([PhoneNumber] <> [AlternatePhoneNumber]
OR [PhoneNumber] IS NULL
OR [AlternatePhoneNumber] IS NULL)
AND NOT ([PhoneNumber] IS NULL
AND [AlternatePhoneNumber] IS NULL));
GO
--OUTPUT
New Approach:(Using IS DISTINCT FROM)
The complexity and length of where clause has been reduced by the new enhancement which comes with the name IS DISTINCT FROM which takes all unique records of two columns as well as return single null values and drop where both columns are null as shown below:
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
WHERE [PhoneNumber] IS DISTINCT FROM [AlternatePhoneNumber];
GO
--OUTPUT

Example 2:
- IS NOT DISTINCT FROM
Old Approach:(Using Complex WHERE Clause)
In old methodology if we had to take same values from two columns and also where both columns have null values, then the query would be as shown below:
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
WHERE
(NOT ([PhoneNumber] <> [AlternatePhoneNumber]
OR [PhoneNumber] IS NULL
OR [AlternatePhoneNumber] IS NULL)
OR ([PhoneNumber] IS NULL
AND [AlternatePhoneNumber] IS NULL));
GO
--OUTPUT

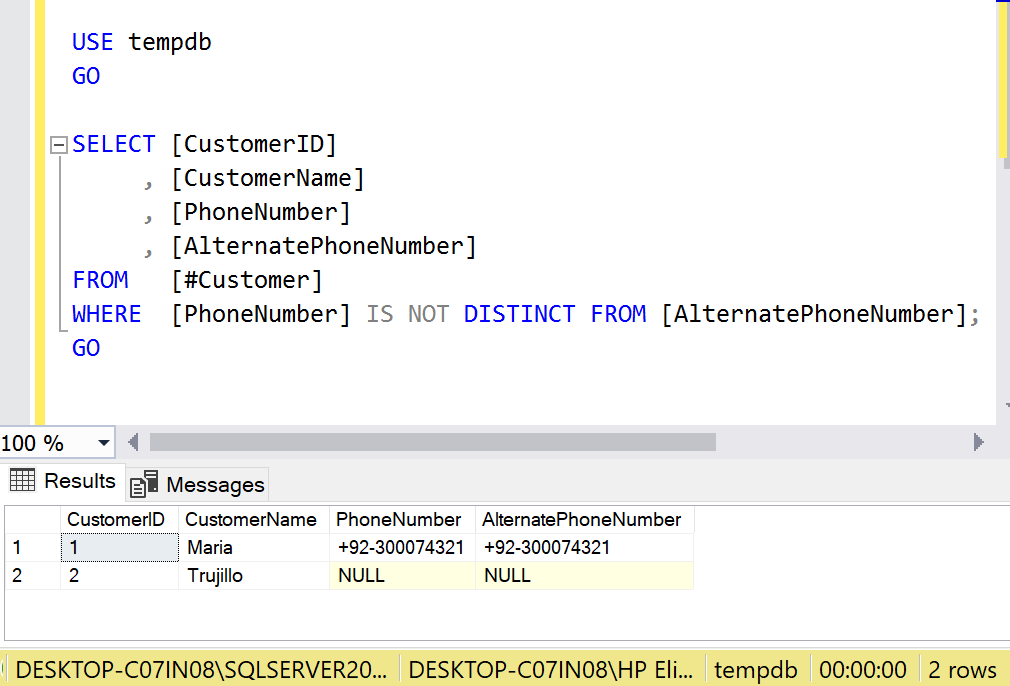
In new Approach, the complexity has been reduced to just single clause named IS [NOT] DISTINCT FROM & rest all conditions are applied by default as shown in the picture below:
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
WHERE [PhoneNumber] IS NOT DISTINCT FROM [AlternatePhoneNumber];
GO
--OUTPUT
Example 3:
- IS DISTINCT FROM
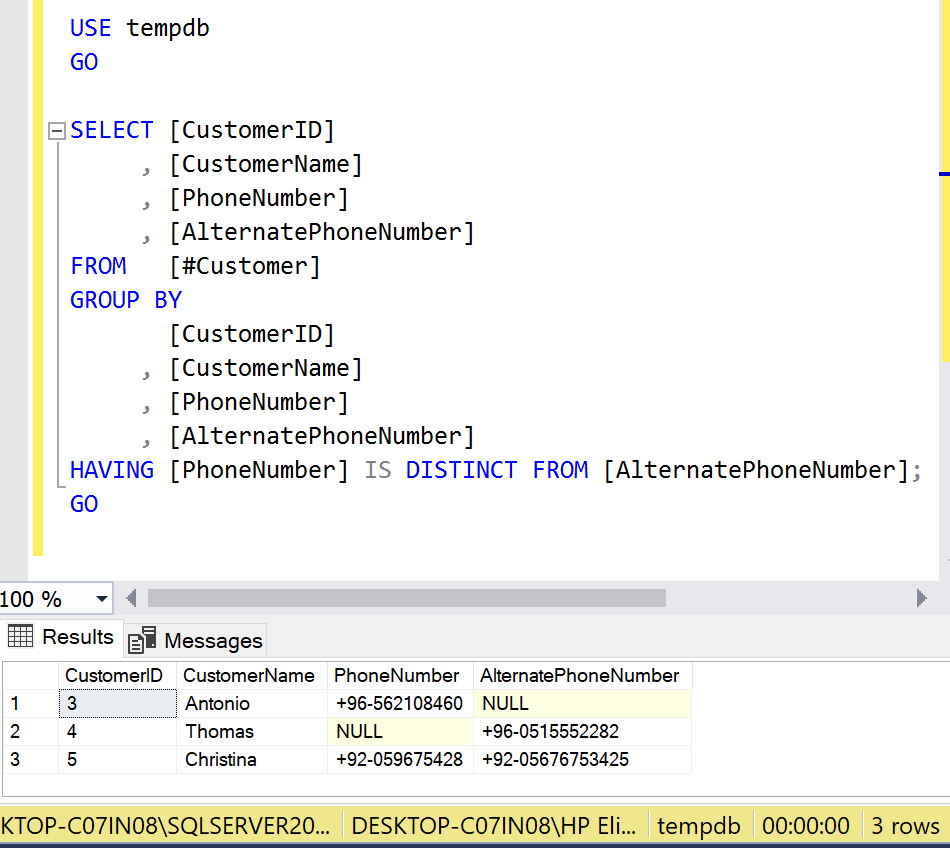
Old Approach:(Using Complex HAVING Clause)
In old methodology if we had to take unique values using HAVING Clause from two columns and also single null values and drop where both columns are null, then the query would be as shown below:
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
GROUP BY
[CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
HAVING
(([PhoneNumber] <> [AlternatePhoneNumber]
OR [PhoneNumber] IS NULL
OR [AlternatePhoneNumber] IS NULL)
AND NOT ([PhoneNumber] IS NULL
AND [AlternatePhoneNumber] IS NULL));
GO
--OUTPUT

New Approach:(Using IS DISTINCT FROM)
The complexity is being reduced by New Approach where we need to write only one clause and rest is handled by itself as shown in the example below.
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
GROUP BY
[CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
HAVING
[PhoneNumber] IS DISTINCT FROM [AlternatePhoneNumber];
GO
--OUTPUT

Example 4:
- IS NOT DISTINCT FROM
Old Approach:(Using Complex HAVING Clause):
In old methodology if we had to take same values using HAVING from two columns and also where both columns have null values then the query would be as shown below.
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
GROUP BY
[CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
HAVING
(NOT ([PhoneNumber] [AlternatePhoneNumber]
OR [PhoneNumber] IS NULL
OR [AlternatePhoneNumber] IS NULL)
OR ([PhoneNumber] IS NULL
AND [AlternatePhoneNumber] IS NULL));
GO
--OUTPUT

New Approach:(Using IS NOT DISTINCT FROM)
The complexity is being reduced by New Approach where we need to write only one clause and rest is handled by itself as shown in the example below.
USE tempdb
GO
SELECT [CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
FROM [#Customer]
GROUP BY
[CustomerID]
, [CustomerName]
, [PhoneNumber]
, [AlternatePhoneNumber]
HAVING [PhoneNumber] IS DISTINCT FROM [AlternatePhoneNumber];
GO
--OUTPUT
Conclusion:
The IS [NOT] DISTINCT Clause is a life saver where writing a query with multiple conditions just reduced to a single clause. It also reduces the complexity of the query. Do let me know if you used IS [NOT] DISTINCT Clause and found it useful.
