sys.dm_exec_describe_first_result_set_for_object is one of the dynamic management functions introduced in SQL server 2012. This function also displays the first result set metadata information like “dm_exec_describe_first_result_set” dynamic management function, but the major difference is“dm_exec_describe_first_result_set” use for SQL queries and “sys.dm_exec_describe_first_result_set_for_object” use for objects like stored procedure, triggers.
Syntax :
sys.dm_exec_describe_first_result_set_for_object ( @object_id , @include_browse_information )
Parameters :
@object_id : Object ID of stored procedure and trigger only. Data type is integer.
@include_browse_information : It can be from 0 to 2. using this parameter, function returns the additional information. Data type is bit.
Purpose :
The purpose of sys.dm_exec_describe_first_result_set_for_object is to view the metadata information of first result set of any stored procedure or trigger. Lets say, if any procedure or trigger having more than one result set then the meta data information will be displayed for the first result set only.
Note : sys.dm_exec_describe_first_result_set_for_object can not display the meta data of other than “stored procedure or trigger”.
Let me explain it with simple examples :
Example 1 : (View metadata information of first result set of the Stored Procedure) when @include_browse_information=0
Use AdventureWorks2012
GO
Select * from
sys.dm_exec_describe_first_result_set_for_object
(object_id('[dbo].[UDP_Employee]'),0)
--OUTPUT
--Given below are the few columns from the result set. Other than that, there are other important information also available to give you complete details of metadata.
--But if the @include_browse_information=0 then this function will not give you the source data (Source Database, Source Schema, Source Table, Source Column) information.

Example 2 : (View metadata information of first result set of the Stored Procedure) when @include_browse_information=1
Use AdventureWorks2012
GO
Select * from
sys.dm_exec_describe_first_result_set_for_object
(object_id('[dbo].[UDP_Employee]'),1)
--OUTPUT
--If the @include_browse_information=1 then this function will give you the source data (Source database, Source Schema, Source table, Source column) information including the information available in @include_browse_information=0

Example 3 : (View metadata information of first result set of the Stored Procedure having two result set) when @include_browse_information=0
Lets create a stored procedure having two result set.
Create Procedure SP_test As Select top 2 [DepartmentID],[Name] from [HumanResources].[Department] order by [DepartmentID] Select top 2 [BusinessEntityID],[JobTitle] from [HumanResources].[Employee] order by [BusinessEntityID] GO EXEC SP_test
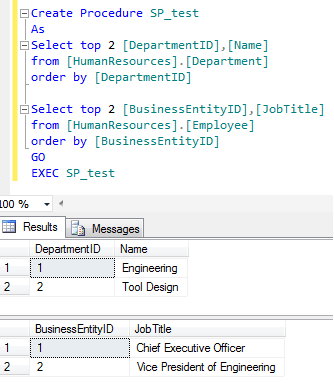
Lets view the meta data information of the first result set of “SP_test” stored procedure using “sys.dm_exec_describe_first_result_set_for_object”
Use AdventureWorks2012
GO
Select * from
sys.dm_exec_describe_first_result_set_for_object
(object_id('[dbo].[SP_test]'),0)
--OUTPUT
--Given below are the few columns from the first result set Only.

Example 4 : View metadata information of View
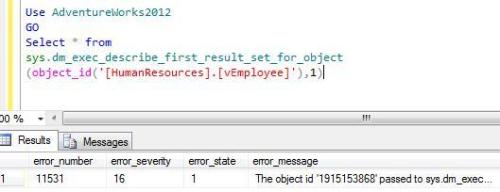
In this example, “sys.dm_exec_describe_first_result_set_for_object” will generate an error because nothing except stored procedure or triggers is allowed.
Use AdventureWorks2012
GO
Select * from
sys.dm_exec_describe_first_result_set_for_object
(object_id('[HumanResources].[vEmployee]'),1)
--OUTPUT
--In this case all values will be NULL expect error information columns in the end of the result set.
--Given below is the screen images of the last columns.
Summary :
sys.dm_exec_describe_first_result_set_for_object gives the meta data information of the first result set of any stored procedure and trigger, but it differs from different @include_browse_information parameter.
- This function can filter the meta data column as per the requirement.
- This function returns the data in a tabular form, so you can utilize it in any other function or procedure.
Reference : MSDN