In SQL Server 2022, a new enhancement was introduced in dynamic data masking known as Granular Permissions which was a long-awaited enhancement. This new enhancement gives us control to provide unmasking permission at lowest level (table’s column) which we could not achieve in the earlier version of SQL Server. In other words, we can give permissions to unmask columns, tables, schemas & databases to different users based on their accessibility levels.
Let me create a sample to demonstrate the functionality of Dynamic data masking granular permissions in which, I will create a Sample database, two schemas and each schema will have one table as shown below.
Sample:
--Create Sample Database
CREATE DATABASE SampleDB;
GO
USE SampleDB
GO
--Create HumanResources Schema
CREATE SCHEMA HumanResources;
GO
--Create Accounts Schema
CREATE SCHEMA Accounts;
GO
--Create Employee Table
CREATE TABLE HumanResources.Employee
(
EmployeeID INT IDENTITY(1,1) NOT NULL PRIMARY KEY,
EmployeeName VARCHAR(250),
Birthdate DATE MASKED WITH (FUNCTION = 'default()') NULL,
Salary DECIMAL(10,2) MASKED WITH (FUNCTION = 'default()') NULL
);
GO
--Create BankAccount Table
CREATE TABLE Accounts.BankAccount
(
AccountID INT IDENTITY(1,1) PRIMARY KEY,
EmployeeID INT NOT NULL,
AccountTitle VARCHAR(250) MASKED WITH (FUNCTION = 'default()') NULL,
AccountNumber VARCHAR(250) MASKED WITH (FUNCTION = 'partial(3,"xxxxxxxxx", 4)') NULL
);
GO
--Insert few records into Employee Table
INSERT INTO Humanresources.Employee(EmployeeName,Birthdate,Salary)
VALUES ('Nancy','1988-12-08','200000'),
('Andrew','1994-07-16','120000'),
('Janet','1994-07-16','75000');
GO
--Insert few records into BankAccount table
INSERT INTO Accounts.BankAccount(EmployeeID,AccountTitle,AccountNumber)
VALUES(1,'Nancy','9922-0105664197'),
(2,'Andrew','0010-0107605278'),
(3,'Janet','4010-3568743987');
GO
Configuration:
Step 1:
Let’s create few users, which will be used to provide relevant permissions to unmask data as shown below.
USE SampleDB GO --Create User HRAdministrator CREATE USER HRAdministrator WITHOUT LOGIN; GO --Create User PayrollAdministrator CREATE USER PayrollAdministrator WITHOUT LOGIN; GO --Create User Accountant CREATE USER Accountant WITHOUT LOGIN; GO --Create User HRManager CREATE USER HRManager WITHOUT LOGIN; GO
Step 2:
Let’s add the db_datareader role in each user created above.
USE SampleDB GO --Grant db_datareader role to HRAdministrator ALTER ROLE db_datareader ADD MEMBER HRAdministrator; GO --Grant db_datareader role to PayrollAdministrator ALTER ROLE db_datareader ADD MEMBER PayrollAdministrator ; GO --Grant db_datareader role to Accountant ALTER ROLE db_datareader ADD MEMBER Accountant; GO --Grant db_datareader role to HRManager ALTER ROLE db_datareader ADD MEMBER HRManager; GO
Step 3:
Let’s provide UNMASK permissions to above created users. The details of the access are as shown below:
- HRAdministrator : can view Birthdate column Data only in Employee table.
- PayrollAdministrator : can view Salary column Data only in Employee table .
- Accountant : can view the entire tables data in Account schema only.
- HRManager : can view the entire data in the SampleDB database.
USE SampleDB GO --Grant Birthday column unmask permission to HRAdministrator; GRANT UNMASK ON Humanresources.Employee(Birthdate) TO HRAdministrator; GO --Grant salary column unmask permission to PayrollAdministrator GRANT UNMASK ON Humanresources.Employee(Salary) TO PayrollAdministrator; GO --Grant Accounts schema unmask permission to Accountant GRANT UNMASK ON SCHEMA::Accounts TO Accountant; GO --Grant entire database unmask permission to HRManager GRANT UNMASK TO HRManager; GO
Testing:
- HRAdministrator
Let’s access the Employee table under the context of HRAdministrator user.
USE SampleDB
GO
EXECUTE AS USER='HRAdministrator';
SELECT EmployeeID
, EmployeeName
, Birthdate
, Salary
FROM Humanresources.Employee;
REVERT;
GO
--OUTPUT

As we can see above, the HRAdministrator can view the Birthdate column data in Employee table but cannot view Salary column data in Employee table.
- Let’s access the BankAccount table under the context of HRAdministrator user.
USE SampleDB
GO
EXECUTE AS USER='HRAdministrator';
SELECT EmployeeID
, AccountTitle
, AccountNumber
FROM Accounts.BankAccount;
REVERT;
GO
--OUTPUT

As we can see above, the HRAdministrator can’t view the data of BankAccount Table since unmask permission is not given.
- PayrollAdministrator
Let’s access Employee table under the context of PayrollAdministrator user.
USE SampleDB
GO
EXECUTE AS USER='PayrollAdministrator';
SELECT EmployeeID
, EmployeeName
, Birthdate
, Salary
FROM Humanresources.Employee;
REVERT;
GO
--OUTPUT

As we can see above, the PayrollAdministrator can view the Salary column data in Employee table but cannot view Birthdate column data in Employee table.
- Let’s access the BankAccount table under the context of PayrollAdministrator user.
USE SampleDB
GO
EXECUTE AS USER='PayrollAdministrator';
SELECT EmployeeID
, AccountTitle
, AccountNumber
FROM Accounts.BankAccount;
REVERT;
GO
--OUTPUT
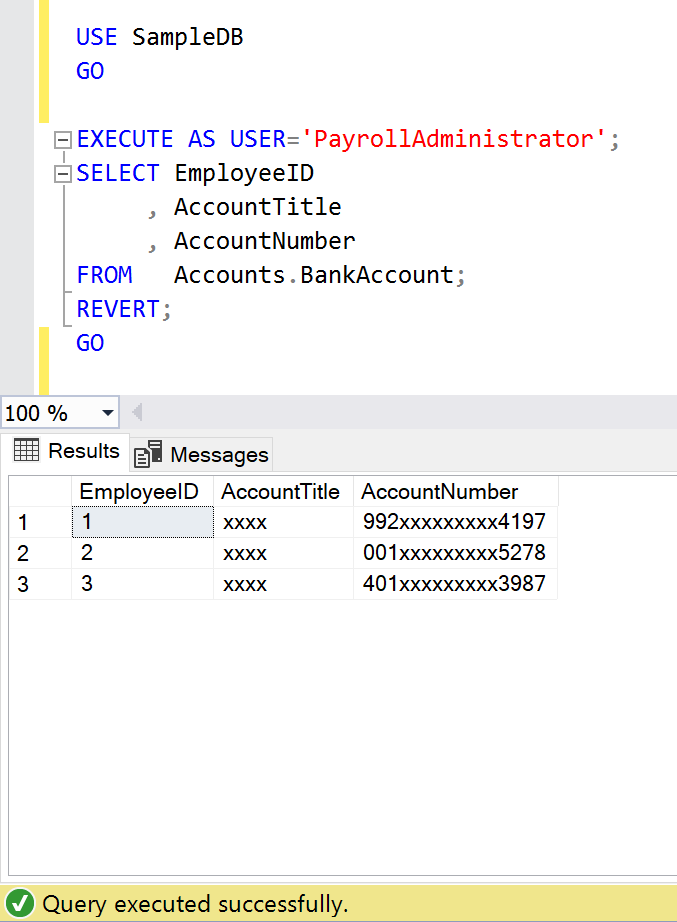
As we can see above, the PayrollAdministrator can’t view the data of BankAccount Table since unmask permission is not given.
- Let’s access the Employee table under the context of Accountant user.
USE SampleDB
GO
EXECUTE AS USER='Accountant';
SELECT EmployeeID
, EmployeeName
, Birthdate
, Salary
FROM Humanresources.Employee;
REVERT;
GO
--OUTPUT

As we can see above, the Accountant cannot view the Salary, Birthdate column data in Employee table since unmask permission is not given.
- Let’s access the BankAccount table which is in Accounts schema under the context of Accountant user.
USE SampleDB
GO
EXECUTE AS USER='Accountant';
SELECT EmployeeID
, AccountTitle
, AccountNumber
FROM Accounts.BankAccount;
REVERT;
GO
--OUTPUT
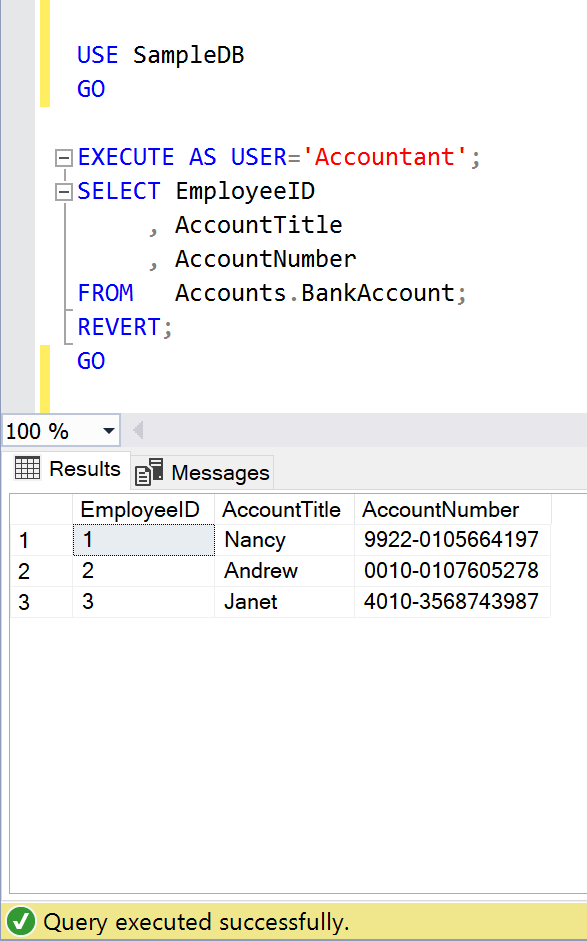
As we can see above, the Accountant can view the data of BankAccount Table.
- Let’s access the Employee table which is in HumanResources schema under the context of HRManager user.
USE SampleDB
GO
EXECUTE AS USER='HRManager';
SELECT EmployeeID
, EmployeeName
, Birthdate
, Salary
FROM Humanresources.Employee;
REVERT;
GO
--OUTPUT

As we can see above, the HRManager can view the data of Employee Table.
- Let’s access the BankAccount table which is in Accounts schema under the context of HRManager user.
USE SampleDB
GO
EXECUTE AS USER='HRManager';
SELECT EmployeeID
, AccountTitle
, AccountNumber
FROM Accounts.BankAccount;
REVERT;
GO
--OUTPUT

As we can see above, the HRManager can view the data of BankAccount Table.
Conclusion:
Granular Permission in dynamic data masking is a very handy enhancement, it gives us the control to unmask column, table, schema, database data to different users. Do let me know if you use it and found it helpful.