I came across this error message while I was working on one of the file tables (A new table concept came in SQL Server 2012) and tried to create a full text index. Most likely this error is related to semantic search (A new type of search concept came in SQL Server 2012).
Let me explain this error in detail :
Message Number: 41202
Severity : 16
Error Message: The source table ‘%.*ls’ specified in the SEMANTICSIMILARITYTABLE, SEMANTICKEYPHRASETABLE or SEMANTICSIMILARITYDETAILSTABLE function doesn’t have a full-text index that uses the STATISTICAL_SEMANTICS option. A full-text index using the STATISTICAL_SEMANTICS option is required to use this function.
Error Generation:
I tried to create full text index on file table and received given below error message.
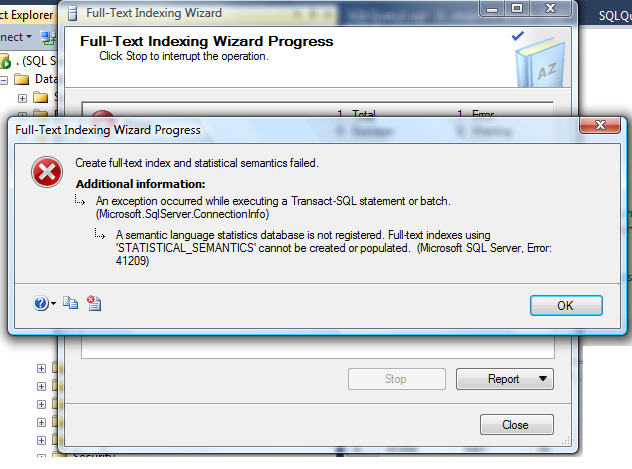
Lets resolve this issue step by step :
Step 1 :
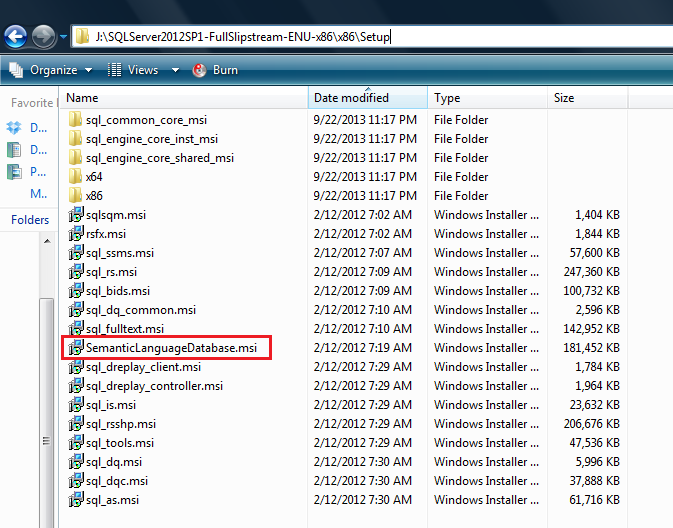
First of all you need to browse the SQL Server installation media and select the given below folder. Here you will find a file namely SemanticLanguageDatabase.msi, just execute this file.
Given below are the different paths for x86 & x64 machines.
• For x86 : …\x86\Setup\SemanticLanguageDatabase.msi
• For x64 : …\x64\Setup\SemanticLanguageDatabase.msi
Given below is the screen image of this folder.
Step 2:
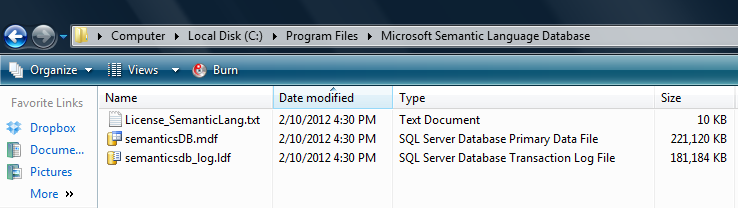
Once you run the above SemanticLanguageDatabase.msi and install it, it will give you two database files (semanticsDB, semanticsdb_log) in a location (C:\Program Files\Microsoft Semantic Language Database), if you install it in the default location.
Given below is the image.
Step 3:
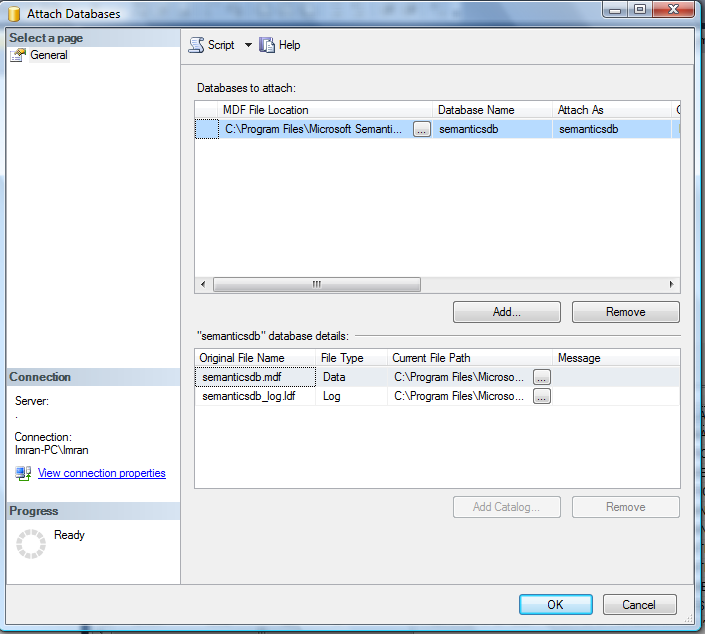
Once we extract the semantic database files (semanticsDB, semanticsdb_log), attach in your database server. Given below is the image.
Step 4:
Once you attach the file in your database, just register the semantic database. Given below is the script.
EXEC sp_fulltext_semantic_register_language_statistics_db @dbname = N'semanticsdb' GO
Now your semantic database has been registered. You can create full text indexes on file tables without any errors.










