I am writing this article in response to one of my junior database developer’s questions, how to insert Arabic data in SQL table, as he had inserted few Arabic names in the table. However, once he selected the data after insertion he found ????? instead of Arabic text in the field. This is a general problem with developers when they work for multi lingual (other than English) environment.
Lets generate this issue step by step.
Step 1 :
First create a table to demonstrate it.
Create table test ( [Employee ID] int identity(1,1), [Employee Name] varchar(50) )
Step 2 :
Insert Arabic text (any non-English text) into the table.
Insert into test ([Employee Name]) values('عمران')
Step 3 :
Browse the data from table.
Select * from test --OUTPUT
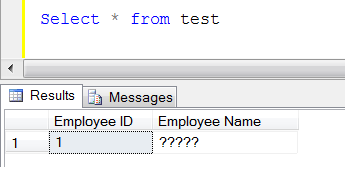
Oooops, it became garbage (?????)
Resolution :
Lets resolve it step by step.
Step 1 :
As you can see, the [Employee Name] (Column) has a data type of varchar, so you need to change it to nvarchar data type. Given below is the script to change it.
Alter table dbo.test Alter column [Employee Name] nvarchar(50)
Step 2 :
Insert the same record again with additional N before name.
Insert into test ([Employee Name]) values(N'عمران') --OUTPUT

Step 3 :
Browse the data from table.
Select * from test --OUTPUT

Conclusion :
Whenever you insert any language (other than English) text into SQL table you must check two things :
- Data type of the field must be nvarchar.
- Insert N before the text.
















